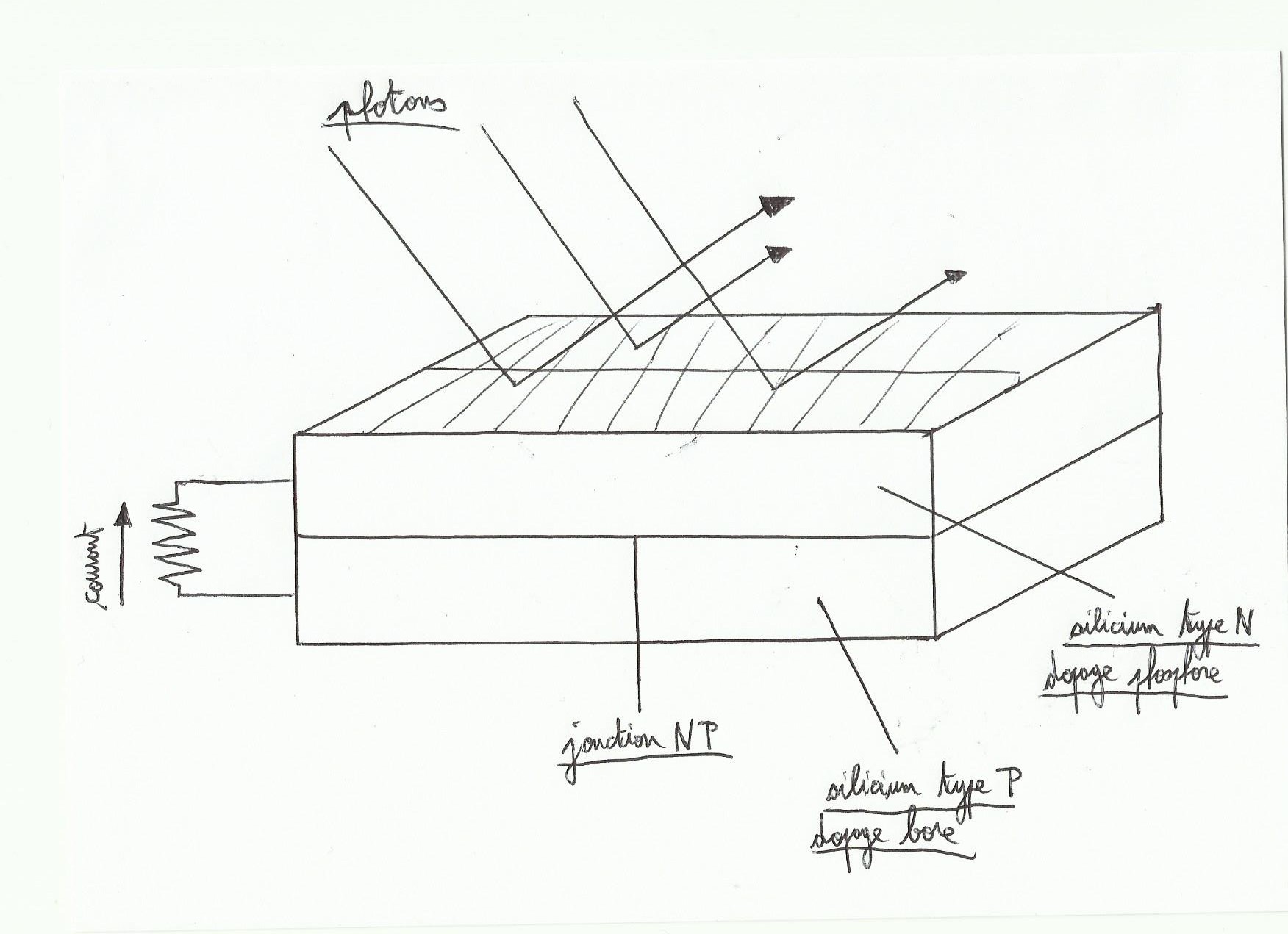
Pour les bateaux en polyester, il existe un choix de résines aux propriétés différentes. Ce choix va dépendre du tissus de fibres utilisé, du procédé de réparation ou de fabrication , des caractéristiques recherchées et bien sûr du coût. Les caractéristiques principales de ces résines sont la résistance aux UV, à l’humidité, à la température élevée, le retrait(perte de volume au séchage), la thixotropie(viscosité de la résine).
1)La résine polyester
C’est la plus courante en raison de sa grande fourchette d’utilisation et de son prix. Cette résine liquide se solidifie(polymérise)grâce à l’addition d’un catalyseur(du peroxyde organique, en général du PMEC), et le démarrage de la réaction se fait avec un accélérateur, le cobalt. L’accélérateur permet de contrôler le temps de gel, le catalyseur équilibre plutôt le temps de gel à la température ambiante. De toute façon maintenant, pour des raisons de sécurité la plupart des résines sont préaccélérées, le cobalt est déjà présent et l’on ajoute juste le catalyseur(on ajoute entre 1 et 3% de catalyseur à la résine, plus il fait froid et humide, plus on en met. En moyenne on met 2%). Il ne faut jamais en mettre trop sinon la résine ne prend pas bien(craquelures, en plus le pot du mélange peut chauffer et fondre), pas assez ça ne polymérise pas.
Il y a deux types de résines polyester, les résines isophtaliques et orthophtaliques; ces dernières sont les plus utilisées car bon marché, mais elles sont moins résistantes à l’eau(absorption d’eau importante)et donc plus vulnérables à l’osmose(infiltration lente et progressive d’eau dans les coques en polyester). En plus leurs propriétés mécaniques sont également moindres. En fait pour le nautisme il faut utiliser de la résine iso(meilleure imprégnation des tissus, meilleure résistance à l’eau et aux agents chimiques, c’est mieux quoi!).
Les résines poly peuvent être chargées(silice, microbilles de verre…)pour augmenter leur thixotropie afin de faire du mastic ou de l’enduit pour reboucher des trous par exemple. Elle s’utilise pour imprégner les tissus de verre, de kevlar, mais pas avec le carbone. Lors de l’imprégnation des tissus, il faut toujours alterner une couche de roving(tissus tramé)avec une couche de mat(tissus avec de la fibre en vrac). Pour une bonne finition le mieux est de toujours commencer et finir par une couche de mat(plus facile à poncer), il faut deux fois plus de résine pour imprégner du mat correctement par rapport au roving.
Le principal problème avec les résines iso c’est l’absorption d’eau, en effet leur reprise d’humidité peut-être importante, entrainant une baisse des qualités mécaniques pouvant mener au délaminage(couches de strate se décollent, youpi…). Pour protéger la résine iso de l’humidité on doit l’isoler, pour cela on emploie un gel-coat ou une peinture polyuréthane(bi-composant)sur le stratifié.
Pour résumer: employer de la résine iso, toujours protéger la fibre avec gel-coat ou peinture bi-composant, lors de la stratification alterner mat/roving, durcit avec du catalyseur(PMEC)pas plus de 3%, mauvaise tenue sur le bois, peut imprégner le tissus de verre ou kevlar mais pas le carbone.
2)La résine époxy
Plus chère, mais beaucoup d’avantages. Sa reprise d’eau est très faible, elle a une meilleure qualité mécanique, résiste mieux au vieillissement et au délaminage. On obtient aussi un meilleur rapport poids/volume, non négligeable pour la course par exemple. C’est la résine la plus imputrescible, elle adhère sur tout quasiment(donc le bois contrairement à la résine poly). Bref c’est le top! Par contre sa résistance aux UV est médiocre. Les stratifié en époxy donnent une meilleure isolation thermique également.
Pour le séchage on utilise cette fois un durcisseur(en général un volume de durcisseur pour deux volumes de résine, de toute façon c’est indiqué sur les pots), par contre le rapport volumétrique entre les deux doit être le plus précis possible et la température doit être optimale sinon ça ne prend pas. Cette résine peut aussi être chargée avec de la silice(pour contrôler la viscosité de la résine, augmenter la densité du mélange), des micro-fibres(collages bois) ou du micro-ballon(enduits à basse densité, renforts dans l’âme pour passer un boulon ou couler un renfort).
Quand on imprègne du tissus avec de la résine époxy, on n’utilise pas de mat. On peut l’employer pour du tissus carbone. Le faible retrait de cette résine permet d’utiliser moins de quantités également.
Pour protéger le stratifié époxy des UV on applique dessus une peinture polyuréthane, le gel-coat ne tient pas. En fait il y a une petite phrase à retenir pour l’époxy: « l’époxy tient sur tout mais rien ne tient sur l’époxy( excepté les peintures bi-composantes) ».
Pour résumer: excellente résistance à l’humidité, excellente qualités mécaniques, peu de retrait, mauvaise résistance aux UV, mise en œuvre plus exigeante(dosage durcisseur/résine, température, hygrométrie), utilisable pour stratifier le bois ou imprégner le carbone, pas de mat utilisé lors de l’imprégnation,nettement plus chère en revanche. Protection aux UV par peinture polyuréthane. Autre petit détail une fois séchée elle est plus difficile à poncer.
3)La résine vinylester
Elle se situe chimiquement entre la résine polyester et la résine époxy, le prix également. On peut stratifier du vinylester sur du polyester, et comme cette dernière on utilise du mat.
4)Le gelcoat
C’est une résine faite avec différentes charges, elle protège le stratifié et donne un rendu final lisse; en général il est pré-accéléré et durcit avec un catalyseur. D’origine il est de couleur blanche pour réfléchir la lumière du soleil et mieux protéger des UV, on peut cependant ajouter un colorant pour lui donner une couleur choisie. Il existe des gelcoats utilisables dans les moules sans paraffine et des gelcoats pour réparation ou application sur la coque avec paraffine(permet au gelcoat de sécher à l’air libre).
5)Matériel de base
Quand on utilise de la résine il faut toujours prévoir une petite balance électronique pour peser précisément les quantités et une pipette graduée pour faire des mélanges bien équilibrés, des culs de bouteille plastique secs et surtout bien se protéger les yeux et les mains. Contre les dégagements de styrène il faut toujours porter un masque à cartouche.
6)L’osmose
C’est le principal problème rencontré par les coques en polyester quand elles vieillissent. Les signes de détection sont simples: il y a formation de petites cloques sur les œuvres vives de la coque, et on peut détecter pour les cas avancés une odeur de vinaigre(acide acétique) dans les fonds du bateau, en perçant les cloques on détecte aussi cet acide acétique. L’osmose est une réaction chimique, elle s’explique facilement en prenant le cas(pas très funky je l’admet)d’un naufragé en manque d’eau douce qui craque en buvant de l’eau de mer(houlà pas bien!).
Boire de l’eau riche en sel déshydrate, cela est dût aux membranes des cellules. C’est une membrane semi-perméable qui protège les molécules de la cellule, elle laisse passer les molécules nécessaires à la vie mais pas les autres. En fait ses pores réduits ne laissent passer que les très petites molécules(oxygène, gaz carbonique, eau pure…)et les grosses molécules(ions du sel dissous dans l’eau)ne peuvent pas passer. Si les solutions des deux côtés d’une membrane semi-perméable ont la même concentration, le milieu est équilibré et les molécules restent chacun de leur côté bien tranquillement. Si les concentrations sont inégales, alors les molécules d’eau passeront d’un côté ou l’autre de la membrane pour rétablir l’équilibre, c’est l’osmose. Donc l’absorption d’eau salée crée un milieu extracellulaire plus concentré en sel que le milieu intracellulaire, pour rétablir une concentration homogène la cellule va « donner » de l’eau au milieu extracellulaire, et se déshydrater(un poisson d’eau douce que l’on balance en mer meurt par déshydratation).
Pour une coque en polyester c’est un peu le même principe, de l’eau pénètre dans le polyester et détruit petit à petit la résine. Pourquoi? parce que lors de la fabrication de la résine il se crée de petites cavités dans la coque remplies d’un liquide très concentré en acides, il arrive que le catalyseur employé n’ai pas imprégné parfaitement tout les recoins de la fibre. Du coup dans ce cas ci l’eau franchit le gelcoat(la membrane semi-perméable)pour baisser la concentration en acides du liquide dans la cloque. Par hydrolyse il se forme alors de l’acide acétique, et le volume d’eau augmente et ne peut plus ressortir. Comme l’eau douce est moins concentrée en ions que l’eau de mer, alors les réactions d’osmose sont encore plus importantes en eau douce(lacs, rivières).