Les dépressions des régions tempérées proviennent en grande partie des changements du jet Stream polaire, ce dernier confronte le déplacement de la masse d’air froid de la cellule polaire et de la masse d’air plus chaud de la cellule de Ferrel.
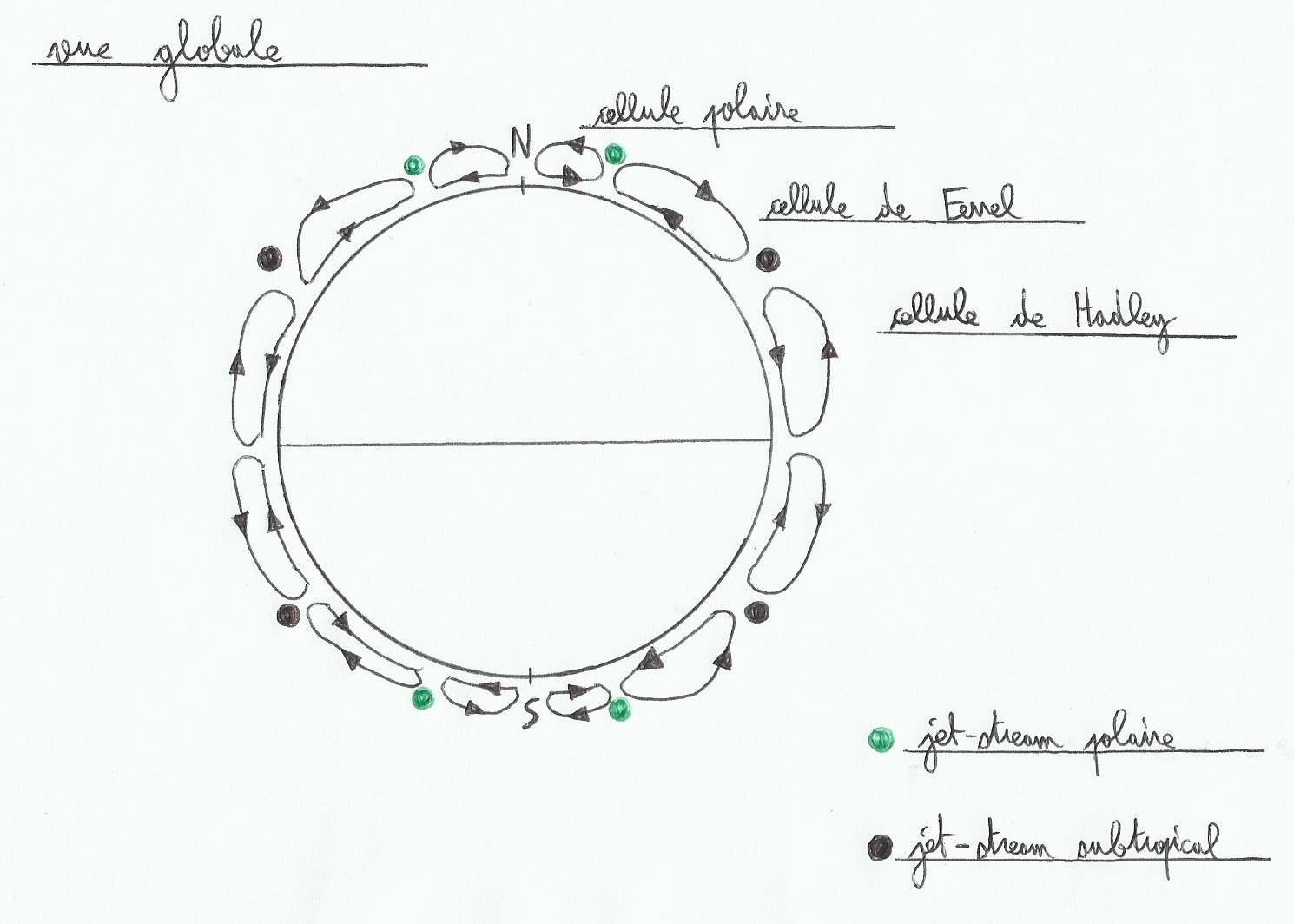
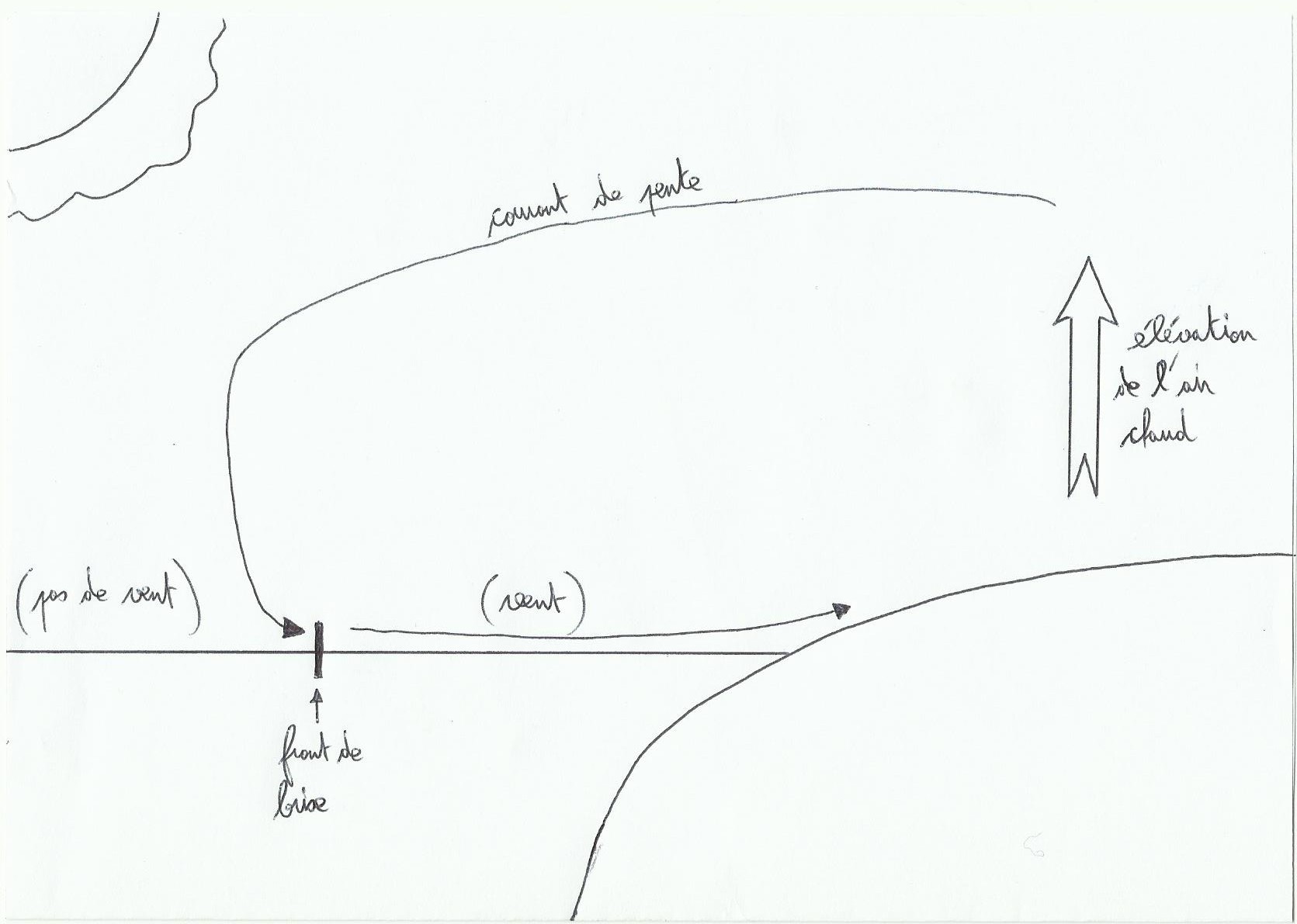
Les cellules convectives fonctionnent un peu comme des engrenages, l’air chaud prend de l’altitude, en montant il refroidit, en refroidissant il devient plus dense, s’alourdit et redescend. Si la terre était plus petite il y aurait moins de cellules convectives.
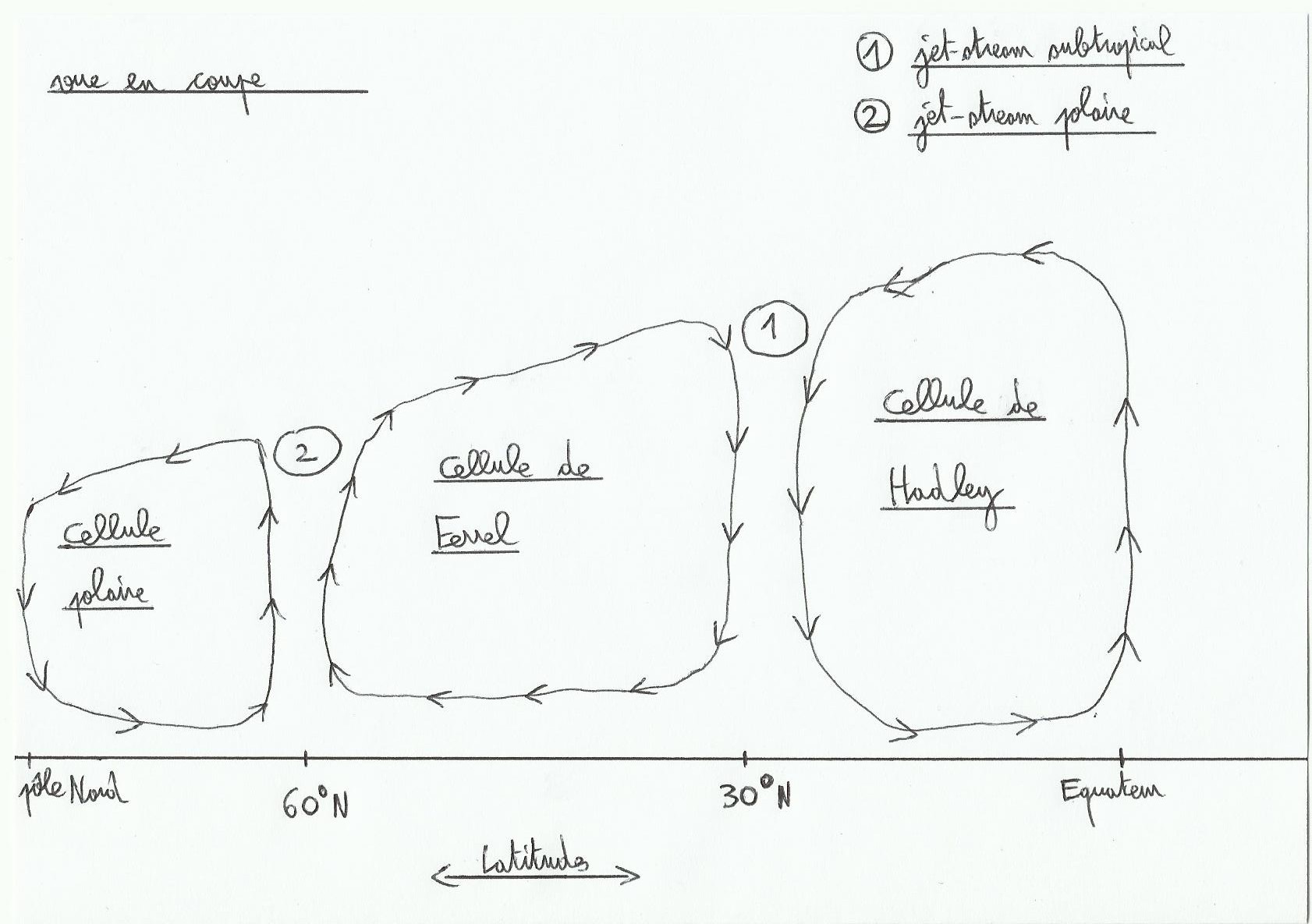
Le jet Stream polaire est plus fort et plus bas en altitude par rapport au jet Stream subtropical. Les jet Stream suivent une trajectoire circulaire ondulée autour du globe, formant de forts vents d’ouest à cet endroit.
Le jet Stream polaire ne souffle pas à vitesse constante, n’avance pas de façon rectiligne et n’est donc pas régulier. Il change de vitesse selon ses virages ou ses méandres comme une rivière, provoquant l’entassement ou la dispersion d’air selon les endroits. Quand il y a entassement on parle de convergence(tendance à faire descendre de l’air à la surface), et dispersion on parle de divergence(créer des appels d’air depuis la surface). Ces deux cas de figure sont à l’origine des fronts froids et chauds rencontrés dans une dépression.
Les dépressions sont évolutives et migratrices, dans l’hémisphère Nord elles se forment la plupart du temps près des côtes Américaines dans l’Atlantique Ouest, évoluent sur l’océan et finissent leur vie en Europe du Nord ou à l’Est de la Méditerranée.
1)Les ingrédients d’une dépression
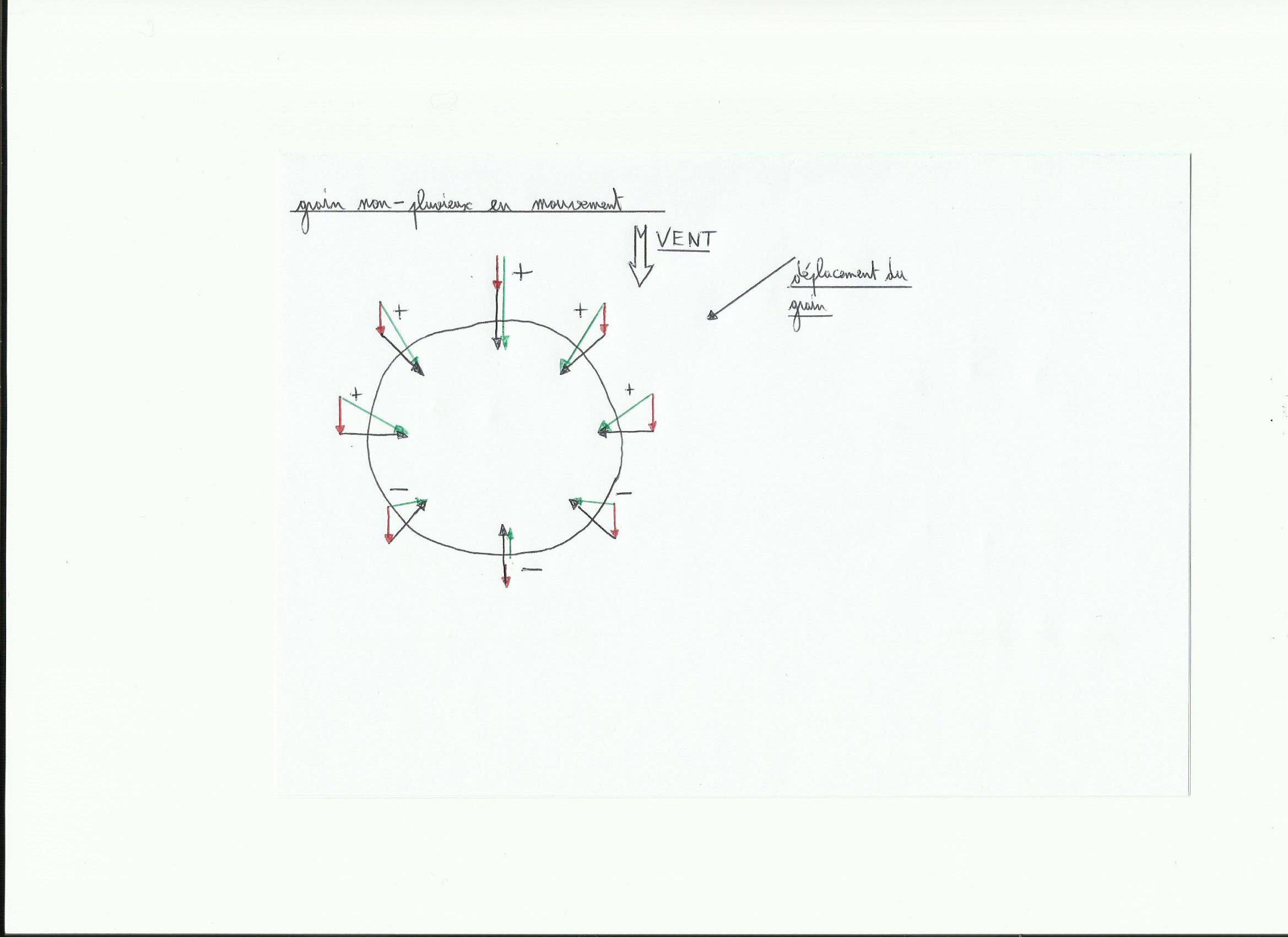
D’après la loi de Buys-Ballot, on sait que le vent tourne dans le sens inverse des aiguilles d’une montre autour des dépressions dans l’hémisphère Nord(inversement dans le Sud).
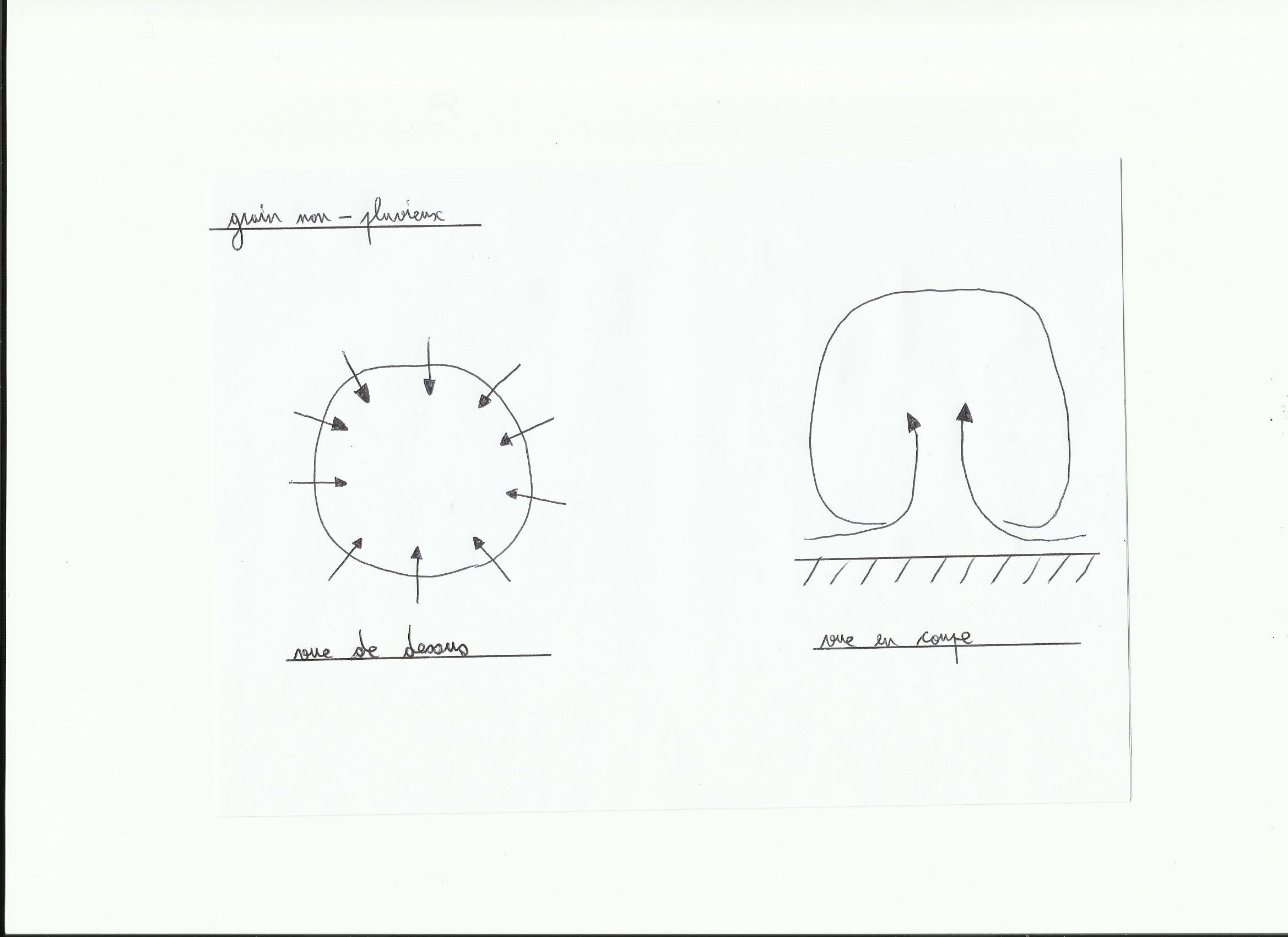
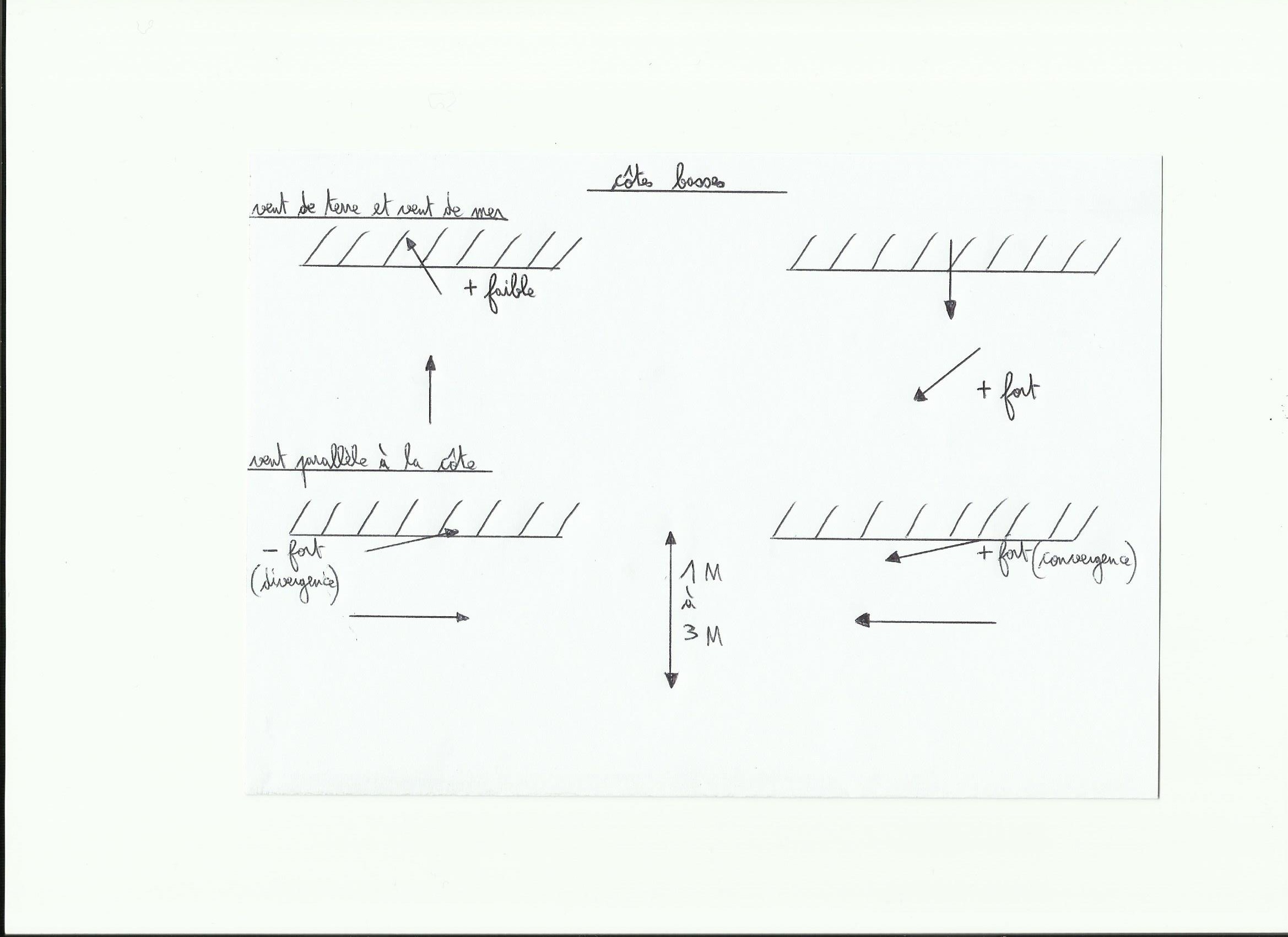
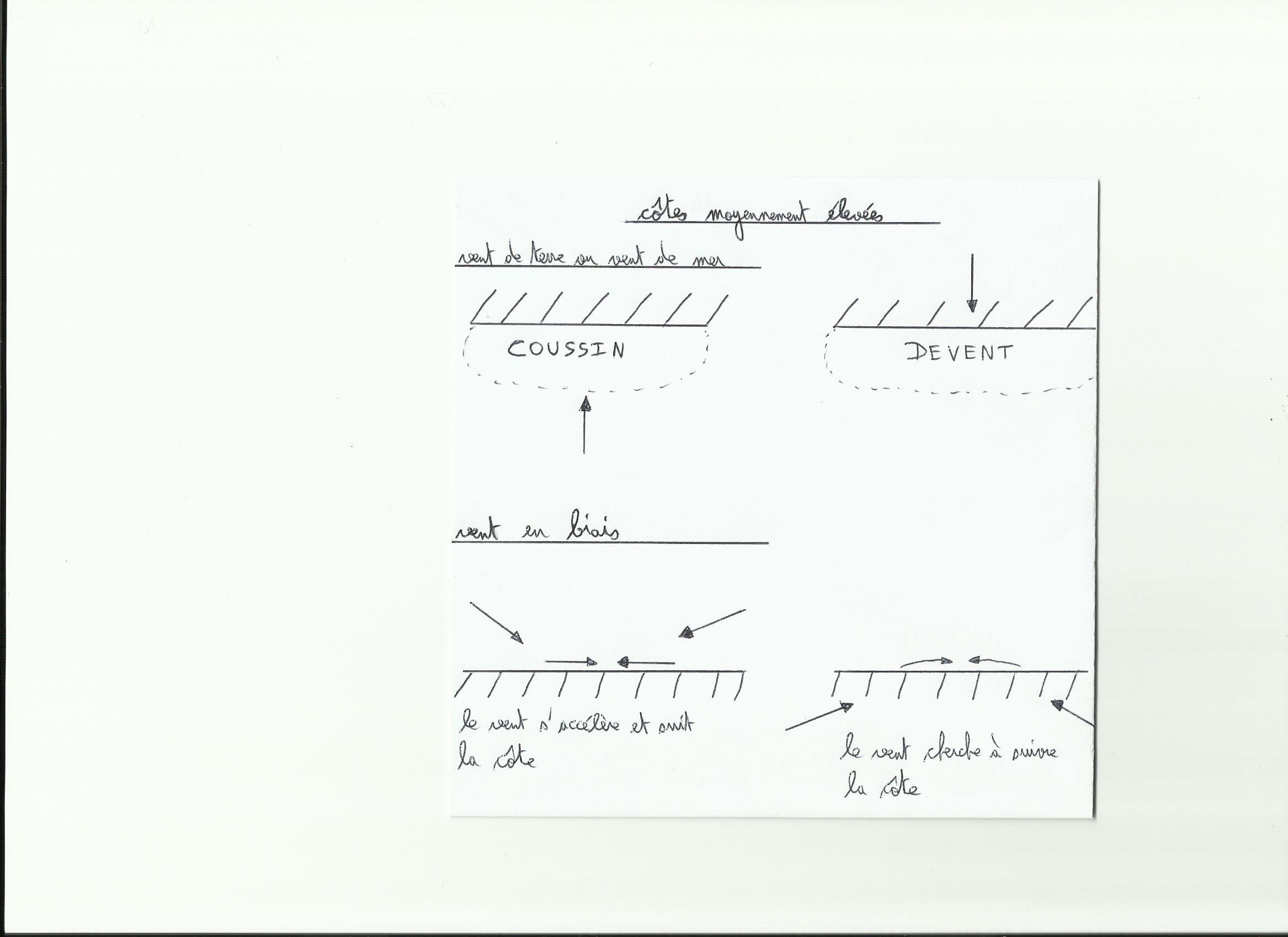
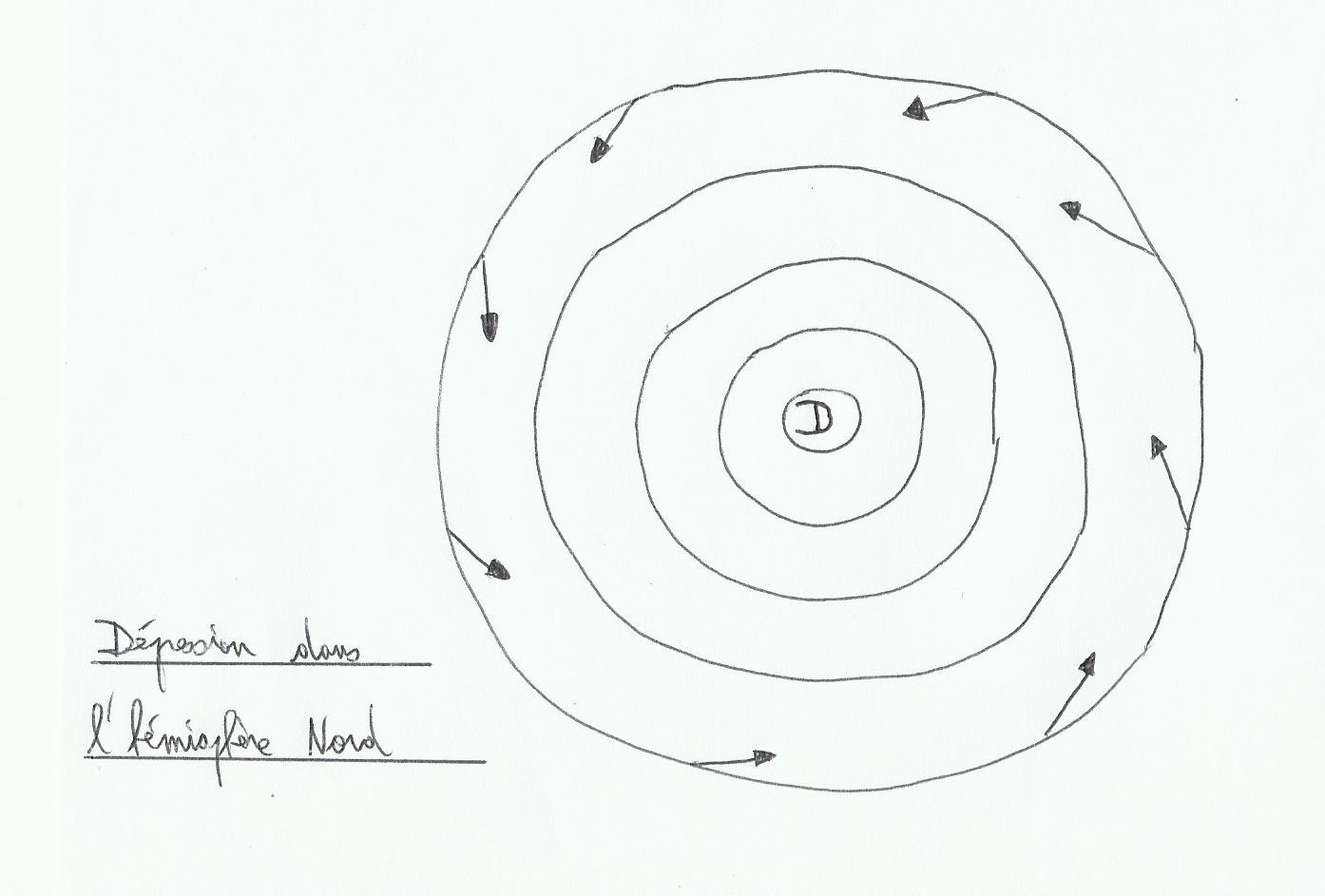 En altitude le vent suit les lignes isobares(lignes d’égale pression atmosphérique)et en surface avec les frottements, le vent rentre dans la dépression en formant environ un angle de 20° avec les lignes isobares. Avec un frottement plus important(sur terre)cet angle va augmenter.
En altitude le vent suit les lignes isobares(lignes d’égale pression atmosphérique)et en surface avec les frottements, le vent rentre dans la dépression en formant environ un angle de 20° avec les lignes isobares. Avec un frottement plus important(sur terre)cet angle va augmenter.
vue d’une dépression en coupe:
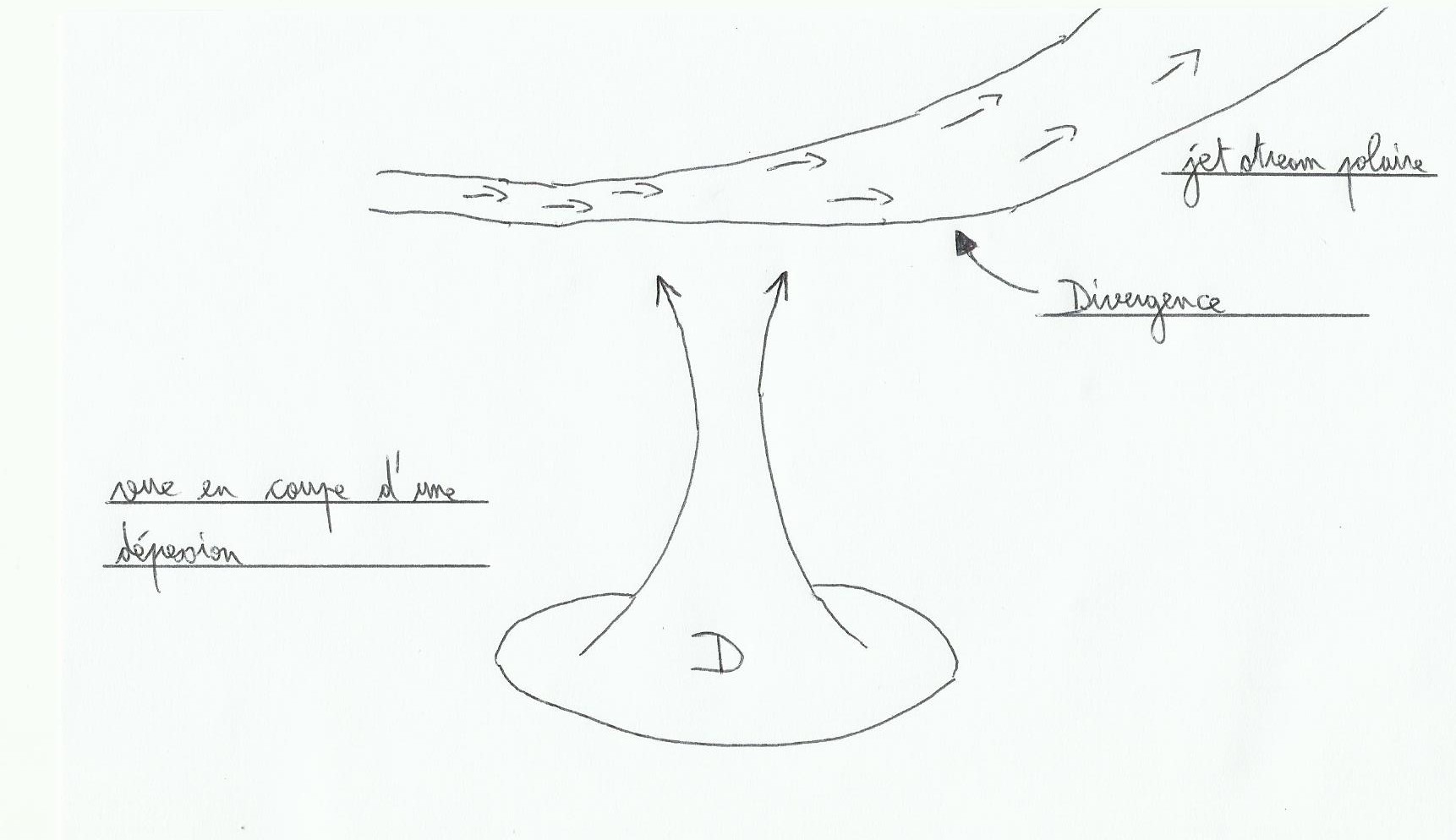
La divergence du jet Stream provoque un appel d’air en surface.
Ce qui caractérise aussi une dépression, c’est la présence des fronts à l’intérieur. Il y a deux types de fronts, le front chaud et le front froid, et deux zones appelées le secteur froid et le secteur chaud(car une dépression n’est autre que la rencontre d’un courant d’air froid et d’un courant d’air chaud sous influence de Coriolis). Pour les dépressions plus « matures » on trouve en plus un front occlus et un point triple.
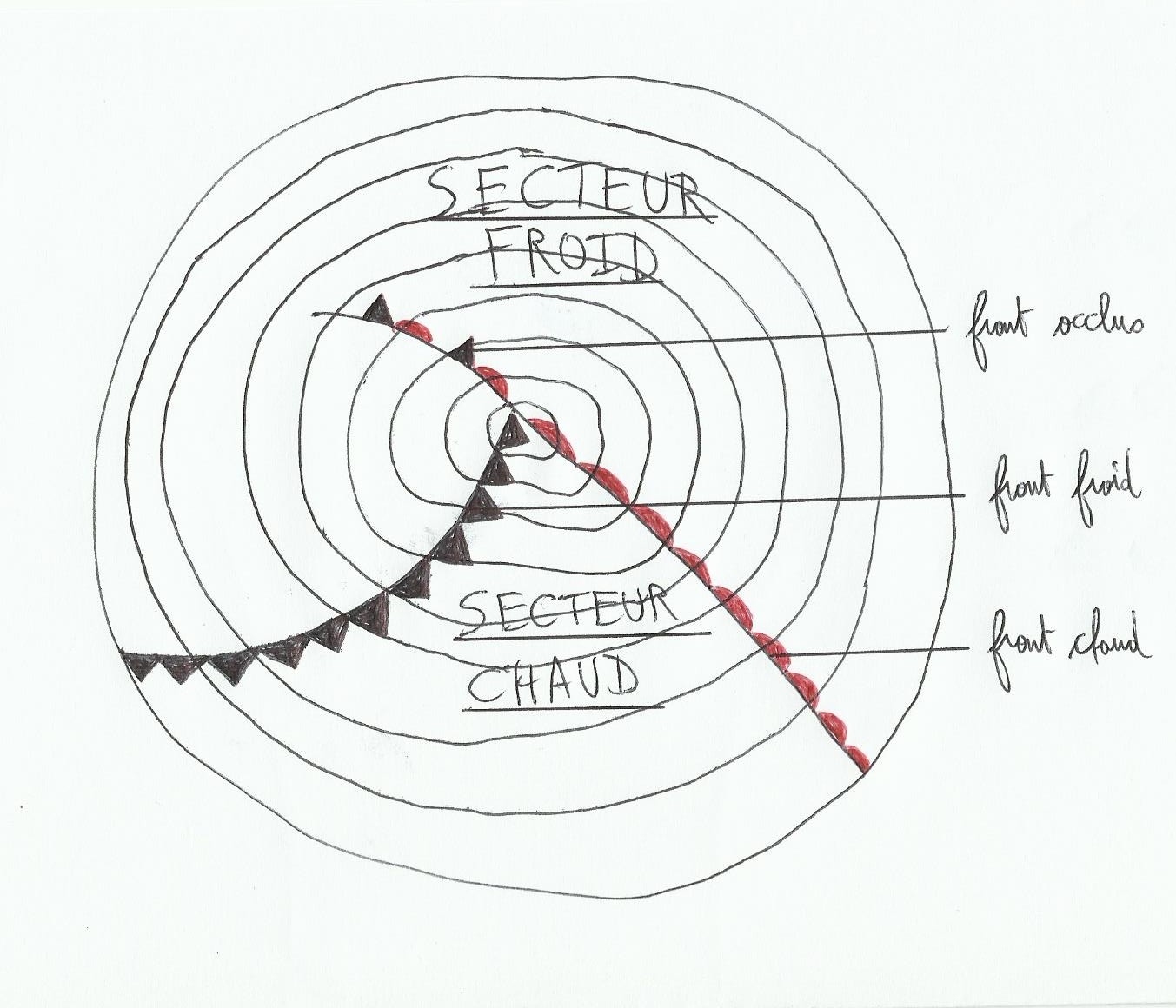
Sur les cartes météo isobares les fronts chauds sont en rouge et les fronts froids en bleu(j’ai plus de stylo bleu du coup…), mais ils sont symbolisés de la même façon. Le point triple est le point de rencontre des fronts.
Quand une dépression se forme, au début il n’y a pas de front occlus et les fronts chaud et froid sont très écartés. En vieillissant, le front froid plus rapide rattrape le front chaud créant le front occlus qui augmente au fur et à mesure que le secteur chaud est rattrapé, et le point triple se décale de plus en plus par rapport au centre de la dépression. Plus la dépression prend de l’âge et plus les fronts vont tourner dans la dépression dans le même sens que le vent.
Front occlus: quand la masse d’air froid a rattrapé la masse d’air chaud, l’air chaud plus léger a été expulsé en altitude. Ces fronts sont généralement caractérisés par une forte couverture nuageuse et de la pluie, moins de vent.
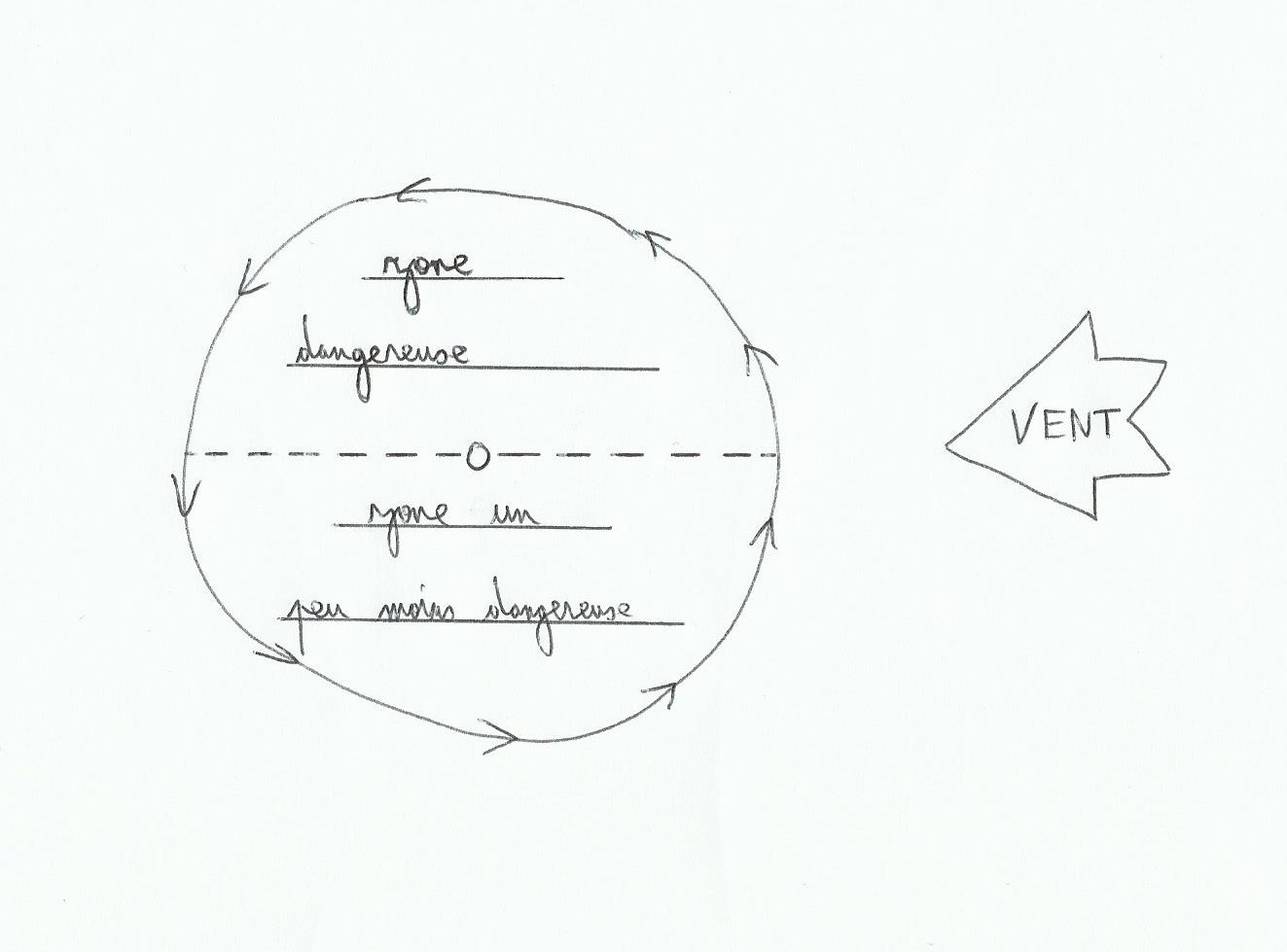
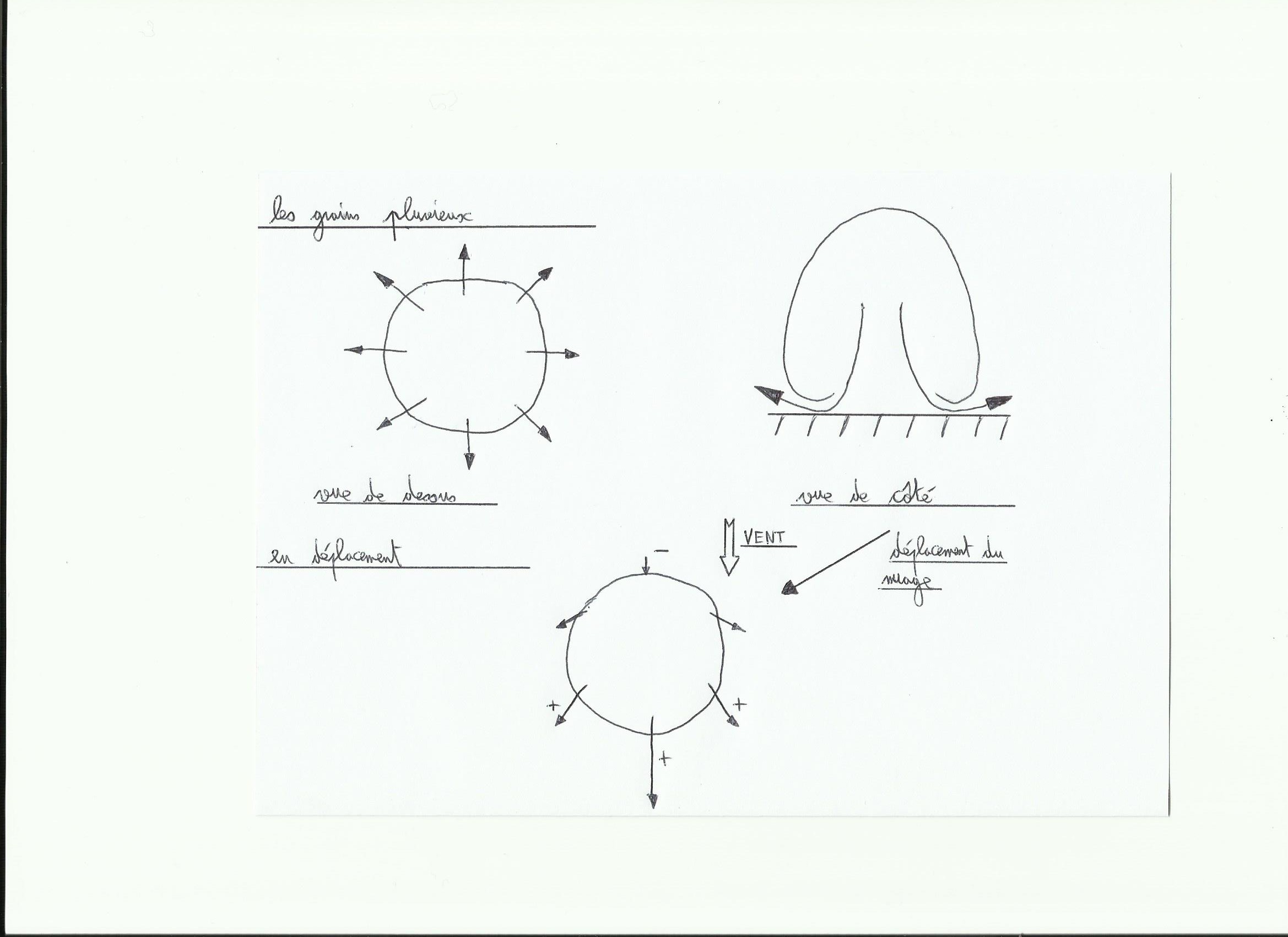
Front froid: quand l’air froid chasse l’air chaud en altitude, cela amène des conditions instables de vent et de visibilité. C’est généralement l’endroit où il y a le plus de vent avec la présence de grains dans une dépression.
Front chaud: Ici l’air chaud monte doucement sur l’air froid, amenant une augmentation progressive de la couverture nuageuse.
2)Les nuages rencontrés
On rencontre différents types de nuages dans une dépression selon l’endroit où l’on est, de plus le baromètre est aussi un outil précieux pour se situer par rapport à ce centre d’action.
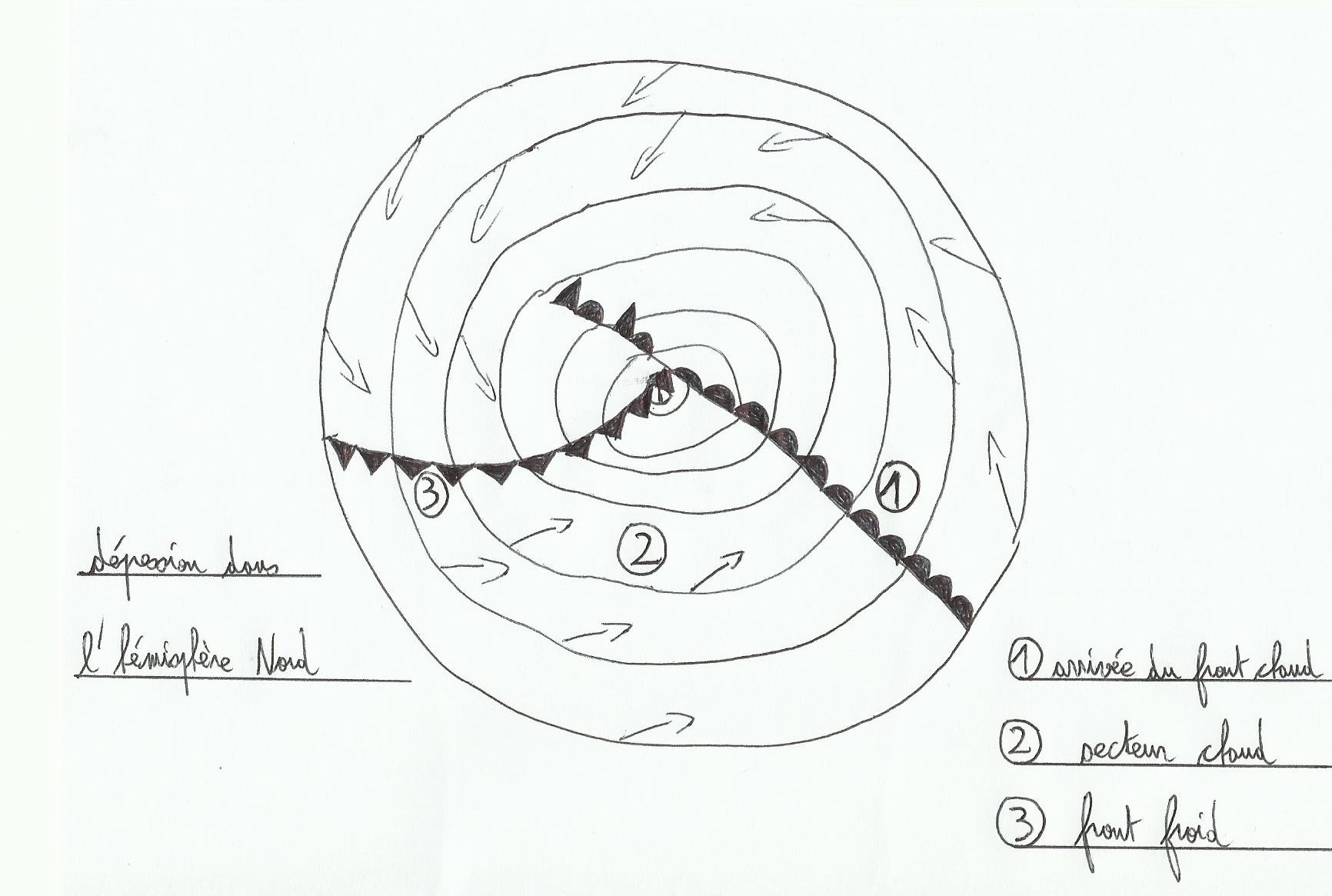
1. Arrivée du front chaud: on observe tout d’abord les cirrus précurseurs(nuages d’altitude en forme de cheveux, filaments)avec une baisse de la pression atmosphérique. Plus les cirrus sont « courbés » plus il y a de chances de voir la situation se dégrader rapidement. Pour l’instant le temps reste clair avec une bonne visibilité. Ensuite viennent les cirrostratus(aussi en altitude), nuages formés de particules de glace ressemblant à des veines blanches, les seuls capables de produire un halo autour du soleil ou de la lune. Si le halo diminue, c’est signe de pluie, d’arrivée du secteur chaud. A ce stade la pression diminue encore et la visibilité à son tour diminue.
2. Secteur chaud: la couverture nuageuse descend et se couvre encore plus, la pression continue de diminuer. Juste avant le front chaud on voit des altostratus(voile grisâtre à travers lequel le soleil ou la lune peut apparaître comme un disque flou)le ciel s’obscurcit. Le front chaud amène une stabilisation de la pression atmosphérique et une couverture nuageuse basse et sombre avec de la pluie(stratus, nimbostratus). Dans le secteur chaud on trouve les stratus qui sont les nuages les plus bas, formant un voile uniforme; la pression est toujours stable et la visibilité est faible. En général dans le secteur chaud les vents viennent d’Ouest ou Sud-Ouest(hémisphère Nord).
3. Front froid: l’arrivée du front froid amène une petite baisse suivie d’une remontée de la pression atmosphérique. La couverture nuageuse encore épaisse se découvre un peu, les grains arrivent. Au front froid on note la présence des cumulonimbus(nuages très étendus verticalement, source de vent fort et de rafales), une remontée rapide de la pression et une augmentation de la visibilité qui se réduit à nouveau sous les grains. Au front froid on note aussi la plupart du temps une bascule du vent au Nord-Ouest.
3)Vie d’une dépression
Jeunesse: les fronts se mettent en place, la pression diminue et l’angle entre les fronts est très ouvert. Le centre de la dépression est superposé avec le point triple, des précipitations apparaissent au niveau des fronts.
Maturité: la dépression se déplace plus vite(entre 15 et 40 nœuds environ), le front froid commence à rattraper le front chaud créant le front occlus, et le point triple se sépare du centre de la dépression. Le vent devient plus fort au front froid, et montre une bascule significative.
Vieillissement: Occlusion importante avec l’approche près de la côte, le centre de la dépression ralentit ou s’arrête. Les pluies augmentent à l’occlusion et le vent est moins marqué dans la dépression, la bascule de vent au front froid est moins significative.
Fin: les fronts ne sont plus différenciés, la dépression ne bouge plus et les fronts ou ce qu’il en reste continuent de tourner dans la dépression tête en bas.
4)La règle des vents croisés
Cette règle bien pratique et assez efficace est un petit plus pour se positionner dans une dépression, et donc pouvoir anticiper la météo à venir(ici, pour l’hémisphère Nord).
On se place face au vent de surface. Avec les vents d’altitude(indiqué par les nuages d’altitude, les cirrus par exemple), on peut avoir des indices sur le déplacement de la dépression:
.Si les vents d’altitude arrivent de la droite, le front chaud approche.
.Si ils arrivent de la gauche, la dépression s’éloigne.
.Si vent surface/altitude sont parallèles, à quelque degrés près bien sûr, et de même sens on est dans le secteur chaud(mais bon en général dans le secteur chaud on ne voit pas les nuages d’altitude, on sait que l’on y est avec la pression stable et la couverture nuageuse dense, basse et pourrie…).
.Si parallèles et de sens contraire, ou est dans le secteur froid, le Nord de la dépression.
Remarque: une houle résiduelle marquée d’Ouest peut aussi être un indice supplémentaire pour l’arrivée d’une dépression.
Il y a plein de bouquins qui expliquent très bien le fonctionnement des dépressions comme « météo et stratégie, croisière et course au large » de Jean-Yves Bernot, le bloc marine est pas mal aussi.