D’après ce qu’on a vu dernièrement, en récapitulant on sait que:
1) L’effet Seebeck permet à partir d’un différentiel de température de générer de l’électricité. Grâce à un composant électrique appelé module peltier, on convertit l’énergie thermique en énergie électrique. D’après une étude de l’insa de Rouen dispo sur le net (Rapport_P6-3_2008_32%20(1).pdf), si sur la face froide du module la température appliquée est de 38 °C et sur la face chaude 90 °C (donc avec un différentiel de 50°C environ) alors en voltage produit on a 1.161 Volts et en puissance on obtient 0.674 watts environ. Le rendement de cet effet reste très faible ( 2.4 %). L’usage du module est déconseillé pour des températures au-dessus de 100 °C (au risque de le cramer) d’après le fournisseur, mais sachant que ces modules sont constitués essentiellement de tellure de bismuth (fusion à 573°C), de cuivre (fusion à 1085°C) et de céramique (fusion au-delà de 2000°C) peut-être peut-on pousser un peu plus le chauffage avant de les faire claquer…
2) Pour avoir un générateur thermique efficace, il doit délivrer un courant électrique régulier, donc il faut que le différentiel de température soie stabilisé. Le problème c’est que généralement au bout d’un moment la partie froide a tendance à se réchauffer, à s’équilibrer avec la partie chaude car elle n’évacue pas toute la chaleur cumulée donc le différentiel de température diminue, et inévitablement c’est la puissance générée par le module qui finit par chuter.
3) Pour avoir une énergie électrique régulière, il faut peut-être envisager l’énergie thermique passant à travers le module un peu comme une rivière qui coule. Si le débit de la rivière est régulier, alors le moulin (le module) va fournir une énergie mécanique (électrique) régulière. L’énergie thermique doit avoir un débit régulier donc.
Donc comment améliorer la partie froide pour avoir un débit thermique régulier ?
Partie 1: un peu de thermodynamique.
La thermodynamique est une branche des sciences qui étudie les échanges d’énergie entre les systèmes, l’énergie se transmet sous forme de chaleur ou de travail (les 2 sont exprimés en joules donc); ici on va s’intéresser à la chaleur. La chaleur s’envisage comme un échange d’énergie entre systèmes sous forme microscopiquement désordonnée (plus la chaleur transmise est forte, plus les atomes véhicules de cette chaleur vibrent en gros), tandis que la température désigne plutôt l’état d’un système particulier (voir le bouquin « Thermodynamique » de R. Taillet par exemple).
Les échanges de chaleur sont souvent assimilés à des variations de température des systèmes impliqués dans ces échanges. On définit cette chaleur par la formule:
Q=CΔT (Q est la chaleur exprimée en joules reçue par le corps, C la capacité calorifique du corps exprimée en joules par kelvin, et ΔT sa variation de température). En étudiant bien cette formule on constate facilement que plus la capacité calorifique d’un corps ou système est élevée, plus ce corps est capable d’ emmagasiner de la chaleur (pour un différentiel de température identique entre 2 corps différents, celui ayant la plus grosse capacité thermique recevra, captera plus de chaleur). Plus la quantité de matière est importante, plus la capacité calorifique l’est (on va y revenir rapidement).
De façon globale un élément dense est meilleur conducteur de chaleur et a une capacité thermique volumique élevée, et un élément léger c’est le contraire (plus isolant, capacité calorifique faible). Les métaux sont de très bon conducteurs de chaleur.
Bref, il faut envisager un truc (avec du métal ?) dense avec beaucoup de matière pour faire une partie froide potable. La mer pourrait donc constituer un corps à capacité calorifique élevée voire même un thermostat idéal pour notre pile (la mer est capable de récupérer la chaleur produite par la pile sans varier de température, comme un thermostat).
Partie 2: pile thermique solaire.
1) Pile essai 1
En premier essai j’avais construit une sorte de caisse rectangulaire, un coffrage isolé thermiquement sur les côtés chauffé à l’intérieur par des lentilles de Fresnel. Les rayons étaient focalisés à l’intérieur sur des collecteurs de chaleur en aluminium peints en noir (peinture de cheminée résistante à 1000°C) et isolés entre eux par du plâtre.
Ces collecteurs étaient en contact avec les modules peltiers, et les modules étaient en contact avec des sections carrées en aluminium également à l’arrière du coffre servant de dissipateurs thermiques, bref de radiateurs. Cette pile comprenait 20 modules peltiers branchés de la façon suivante: 10 en série fois 2 puis les 2 séries de 10 modules en parallèle. Sur un collecteur on avait 2 modules disposés l’un au-dessus de l’autre.
Au final après un essai en octobre par temps ensoleillé normand cette première pile a été capable de délivrer une tension de 4.5 volts de façon régulière pendant environ 20 minutes, pour une puissance très faible (on comptait environ 0.5 watts, c’est pas avec ça qu’on pouvait alimenter en jus le dernier concert de Jean Michel Jarre). Ensuite j’avais essayé de limiter les pertes thermiques en noyant les collecteur dans de la résine époxy (l’idée était de laisser passer les rayons lumineux jusqu’aux collecteurs, mais bloquer la chaleur sortante), mais les lentilles de fresnel ont trop focalisé les rayons (j’aurai dû rapprocher légèrement les lentilles des collecteurs) et du coup ça a tout cramé… Elle marche beaucoup moins bien maintenant, sauf comme table de chevet (lourde en plus) si on des goûts de chiotte.
2) Pile essai 2
Cette fois pour ce nouveau modèle de pile bricolée j’ai utilisé 6 lentilles de Fresnel, 6 modules peltiers, une section rectangulaire en aluminium de 1 mètre de long, 2 tubes de cuivre de diamètre 18 mm, du CP pour fabriquer le support des lentilles, et un rouleau de tuyau de cuivre. Pour les jonctions j’ai utilisé des serflex et du mastique résistant à la température et l’humidité. Ha oui j’ai aussi utilisé un tuyau de jardin :
Pour la fabriquer c’est tout con, sur la section en aluminium j’ai collé les modules peltiers (sur les coins seulement pour ne pas couper le transfert de chaleur), et sur les modules j’ai collé des morceaux de cuivre peints en noir pour bien absorber la lumière focalisée par les lentilles (peinture de cheminée). Ensuite dans la section alu j’ai glissé les 2 tubes de cuivre, puis j’ai bouché les 2 trou de la section avec du mastique en laissant dépasser les tubes de cuivre. Ensuite j’ai bricolé les supports des lentilles en bois en veillant bien à avoir une focalisation pas trop concentrée sur le cuivre peint (sinon ça fait cramer la peinture).
Ensuite j’ai bricolé 2 radiateurs avec le rouleau de tuyau de cuivre. Chaque radiateur est relié à une entrée et une sortie d’un tube de cuivre dans la section alu.
Le fonctionnement est simple: la lentille focalise les rayons solaires sur le cuivre peint qui chauffe, chauffant le module également. Le module peltier est refroidit par la section rectangulaire en aluminium remplie d’eau qui contient les tubes de cuivres reliés aux radiateurs, eux aussi remplis d’eau. En fait la section alu sert d’échangeur thermique entre les modules et les radiateurs.
Résultats:
Cette pile a été testée entre 11h et 13h le 22 août. Comme le circuit des radiateurs n’était pas parfaitement étanche j’ai ajouté 3 bouteilles d’eau pendant ces 2 heures dans les radiateurs. J’ai utilisé de l’eau du robinet à 17°C environ.
11h10: 7.7 volts/plus de 200mA
11h20: 7.8 volts/plus de 200mA
11h30: 7.4 volts/plus de 200mA
11h40 (premier ajout d’eau): 7.8 volts/plus de 200mA
11h50: 7.9 volts/plus de 200mA
12h00: 7.7 volts/plus de 200mA
12h10: 7.4 volts/250 mA
12h20 (second ajout d’eau): 8.1 volts/300mA
12h30: 8 volts/280 mA
12h40: 7.7 volts/270 mA
12h50: 7.7 volts/260 mA
Donc cette pile fournit entre 1.85 et 2.4 watts de puissance. Lors des mesures il a fallu réorienter la pile légèrement toute les 10 minutes pour bien être aligné avec le soleil. Quel est son rendement du coup ?
Dans le bouquin « les indispensables astronomiques et mathématiques pour tous » (A. Moatti), l’auteur nous dit que le flux thermique solaire que l’on capte au sol est en moyenne de 490 watts par m2. Cette valeur varie selon la position du soleil par rapport à notre zénith, l’albédo, la couverture nuageuse… Bref on va se contenter de ce chiffre pour simplifier. Les lentilles que j’ai utilisé ont une dimension chacune de 24.5/17 cm donc en surface 416.5 cm2. Comme j’en ai utilisé 6 ça fait donc 2499 cm2 soit 0.25 m2 environ. Du coup notre pile récupère du soleil à peu prêt 122.5 watts. Donc son rendement est situé environ entre 1.5 et 1.9 %. Il faudra refaire un essai en hiver cette fois pour comparer, après avoir amélioré l’étanchéité des radiateurs. On peut surement encore gratter un peu de rendement.
Partie 3: pile thermique à combustible.
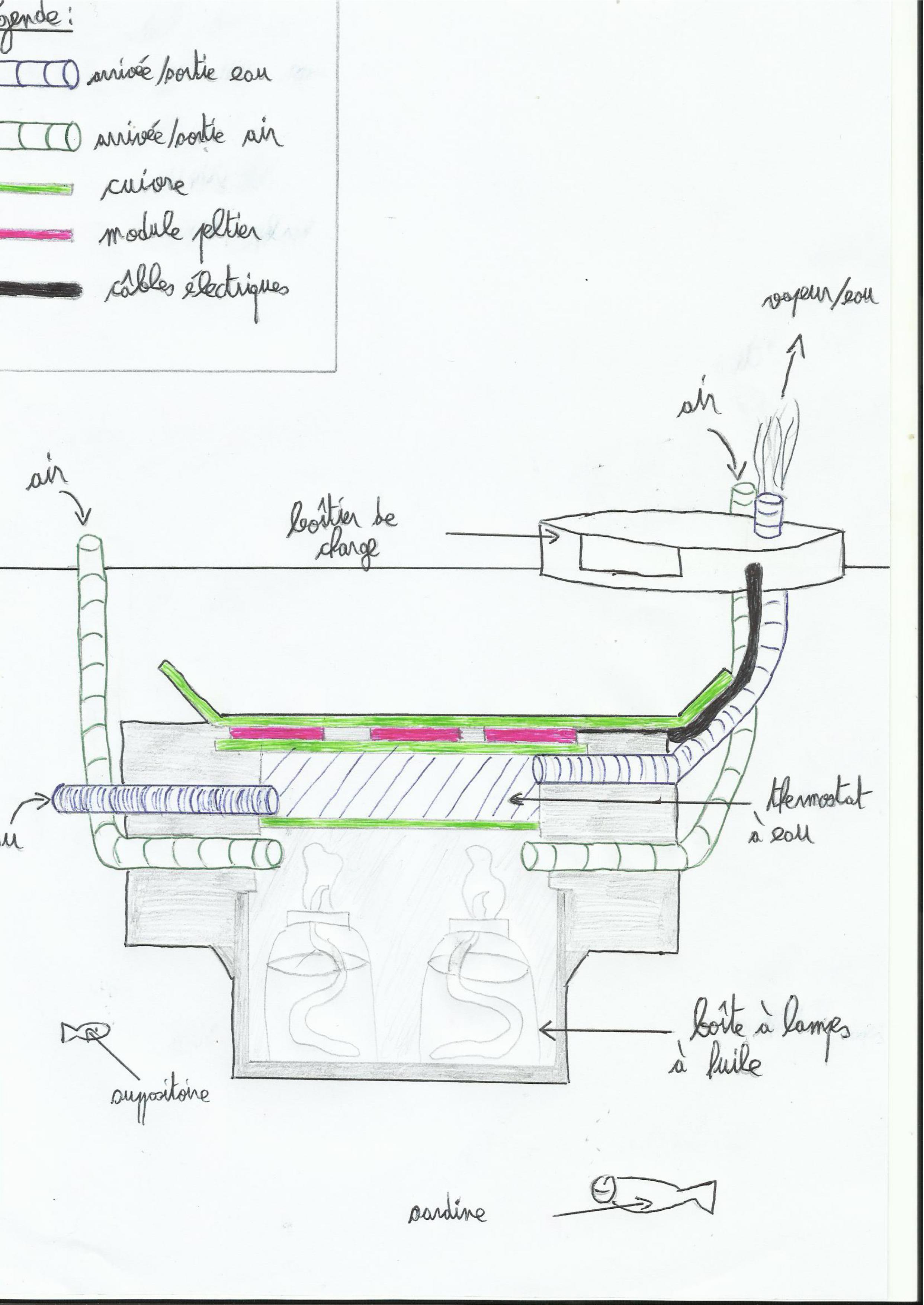
Comme on l’a vu dans l’intro, la mer peut peut-être faire un excellent thermostat pour une pile thermique (donc faire très efficacement circuler la chaleur), du coup actuellement je suis en train de bricoler une pile immergeable qui fonctionnerait avec la combustion de l’huile (friture, colza, olive… Bref de l’huile). Des ou une grosse lampe à huile chaufferait du cuivre qui à son tour chaufferai des modules. La partie froide serait simplement une plaque de cuivre en contact direct avec la mer. Voici un petit schéma du projet:
Pour le moment j’en suis juste à la bidouille de la partie chaude mais ça présente plusieurs problèmes:
– Pour la combustion de l’huile il faut de l’oxygène, or si la partie chaude est immergée, ça risque d’être compliqué d’amener un volume d’oxygène suffisant aux lampes à huile pour obtenir une chaleur efficace et suffisante.
– Si la pile est immergée, alors elle ne doit pas avoir un volume trop important pour ne pas avoir à trop la lester (principe d’Archimède) pour la maintenir sous l’eau.
– Si la pile n’est pas immergée mais flotte sur l’eau, alors il va falloir vraiment bien isoler la partie chaude qui fait le lien entre les lampes à huile et les modules car les pertes thermiques sont très rapides.
– Il va falloir moduler la partie chaude: soit en trouvant le compromis chaleur stabilisée/distance des lampes à huile idéal pour ne pas cramer les modules, ou alors fabriquer un thermostat (voir schéma) pour limiter la température de chauffage des modules (dans le cas du schéma à 100°C donc).
– Bien chauffé, le cuivre se dilate et se déforme un peu ce qui peut endommager les modules si ils sont en prise directe dessus.
Voilà des petites photos pour montrer où j’en suis actuellement:
La boîte contient 9 pots blédina (parfum pomme/mangue, mes préférés) faisant office de lampes à huiles. Cette boîte s’insère dans un couvercle en bois et en cuivre avec 8 trous de 1 cm de diamètre pour laisser passer de l’oxygène pour la combustion. C’est insuffisant car après quelques secondes seul une des neuf lampes reste allumée (la centrale); si je laisse juste cette lampe au bout de 5 minutes elle chauffe la plaque de cuivre à 50 °C environ.
Bon à bientôt pour la partie 4 je vais essayer de pas mettre 2 ans pour la faire cette fois !
D’après les précédents résultats, il a fallu ajouter ou modifier quelques trucs sur le générateur pour essayer de le rendre plus efficace; la partie froide a donc été changée en réservoir à eau (j’ai soudé à froid un autre moule en aluminium sur les bords du moule « partie froide »), les morceaux d’éponge collés sur le pourtour du moule partie froide ont été virés, et l’isolation du moule partie chaude a été améliorée de plusieurs épaisseurs et avec du mastic. Concernant l’emploi du bidule pour l’énergie solaire les miroirs ont aussi viré et ont été remplacé par un pare soleil de voiture argenté (plus efficace et en plus ça ne coûte rien, et c’est plus facile à trouver en récup), la vitre en pvc a été modifié en double vitrage pour améliorer l’isolation.
sur la photo on voit bien le moule soudé, puis l’ajout de silicone sur la soudure pour étanchéifier l’ensemble.
trois couches d’isolant ont été ajoutées, collées à chaque fois au mastic. Sur le bord du moule « partie chaude » j’ai fait un joint en mastic bien plat sur le haut pour améliorer l’isolation de l’ensemble une fois la vitre posée dessus. Quand la vitre est appliquée, elle appuie d’abord sur la mousse de l’isolant avant de toucher ce joint (pour éviter au maximum les pertes de chaleur).
J’ai gardé les charnières articulées avec les cintres, mais cette fois pour capter plus efficacement la lumière j’ai découpé un pare-soleil en 4 morceaux.
Sur la vitre utilisée au début j’ai collé une deuxième vitre, entre les deux il y a un filet d’air de 5 mm environ. De cette façon on obtient une sorte de double vitrage capable d’optimiser l’isolation thermique du bidule.
1) énergie solaire
Quand le générateur est utilisé avec le soleil, comme pour un four solaire il doit être orienté de façon optimale vers la source d’énergie; comme le soleil n’est jamais éternellement fixe dans le ciel il faut donc de temps en temps repositionner correctement la couscoussière. pour que la vitre avec le pare soleil soie bien appliquée sur la pile afin d’ éviter toute perte thermique, j’utilise une paire de sandows.
Par une journée normande d’octobre bien ensoleillée, sans aucun nuage, et avec une eau du robinet à 15 degrés comme refroidissement on obtient ça :
14h55: départ
/15h00: 2V et 74 mA
/15h10: 2.45V et 88 mA
/15h20: 2.7V et 97 mA
/15h30: 2.62V et 87 mA
/15h40: 2.71V et 98 mA
/15h50: 2.92V et 103 mA
/16h05: 2.73V et 90 mA
/16h15: 2.75V et 92 mA
/16h25: 2.56V et 87 mA.
Toujours en octobre, cette fois avec des nuages de temps en temps:
16h20: 0.6V et 20 mA
/16h25: 1.57V et 58 mA(puis éclaircie)
/16h31: 2.55V et 83 mA(ensuite arrivée d’un gros nuage bien gras)
/16h40: 1.75 V et 63 mA (puis hop là bim éclaircie à nouveau)
/16h50: 2.65V et 95 mA
/17h00: 2.63V et 95 mA
/17h10: 2.7V et 96mA (ensuite ça se couvre définitivement)
/17h20: 0.8V et 23mA.
Conclusion: par rapport à la première tentative (réalisée en été, au mois d’août) on gagne environ 1 V de tension et plus d’intensité également. On peut encore optimiser l’ensemble; en améliorant l’isolation thermique de la jonction entre la vitre pvc et le bord de la pile, et pourquoi pas en améliorant le système de refroidissement (qui a tendance à se réchauffer dans le temps, donc à faire baisser la tension obtenue au fur et à mesure).
2) Eau bouillante
Comme on l’a vu au début, on ne peut pas chauffer indéfiniment les modules peltier, si on dépasse les 100 degrés de température, on risque de les cramer tout simplement. si on les réchauffe avec de la vapeur d’eau en ébullition on sera sûr de ne pas dépasser cette limite des 100 degrés, donc de protéger correctement l’ensemble. On place la pile partie chaude vers le bas sur un couvercle aluminium troué pour laisser passer la vapeur, puis l’ensemble sur un récipient d’eau en ébullition:
Il n’y a pas contact direct entre le moule de la pile et le couvercle aluminium grâce au joint mastic ajouté sur le bord du moule « partie chaude » et l’isolation en mousse qui dépasse un peu. En ayant au préalable remplit la partie froide de la pile au maximum avec une eau à 15 degrés on obtient les résultats suivants:
16h13: début
/16h15: 0.5V et 23 mA
/16h20: 7.53V et 2.3 A
/16h25: 7.41V et 2.5 A
/16h30: 6.23V et 2A
/16h35: 5.19V et 1.8A/
16h40: 3.9V et 1.4A
/16h45: 3.4V et 1.1A.
A la fin l’eau du refroidissement était à 29.5 degrés.
Conclusion de l’histoire:
Afin d’avoir une pile thermique efficace, il est nécessaire d’avoir la meilleure circulation de chaleur possible entre la partie chaude et la partie froide (je pense que la chaleur est à envisager comme une rivière devant être à débit constant pour pouvoir entrainer efficacement la roue du moulin, c’est à dire les modules). On va donc essayer de faire 2 piles distinctes; l’une fonctionnant avec le soleil et l’autre avec un combustible simple (bois ou huile par exemple).
Pour la pile fonctionnant avec le soleil je vais essayer de faire une sorte de coffrage isolant chauffé avec des lentilles de Fresnel et refroidit à l’air ou à l’eau, et l’autre pile on verra (probablement chauffée avec un combustible puis refroidie à l’eau).
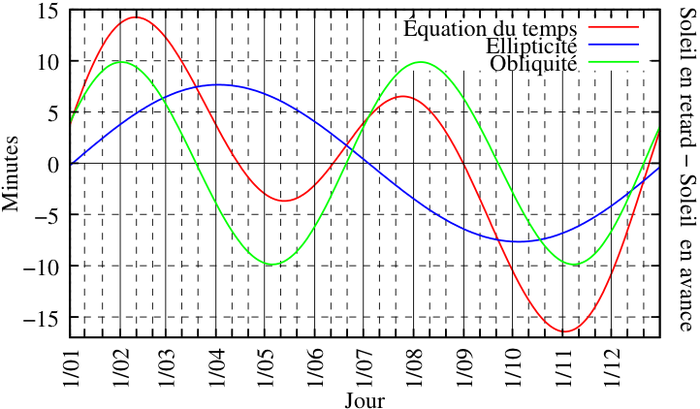
Pour faire un programme permettant de se positionner grâce au Soleil, il a fallu utiliser principalement ce qu’on appelle l’équation du temps, c’est-à-dire la différence entre le temps solaire moyen et le temps solaire vrai. Cette équation induit donc la vitesse « réelle prise à l’instant t » de la Terre autour du Soleil, vitesse non constante dans le temps suite à sa trajectoire elliptique (voir lois de Kepler). Maintenant nous allons voir comment a été obtenue cette équation, la méthode trouvée devrait peut-être nous permettre de la réinvestir plus tard dans le calcul des trajectoires des planètes également utiles à la navigation (Mercure, Vénus, Mars, Jupiter, Saturne), sachant que pour établir un programme de positionnement avec les planètes il faudra également se taper un changement de référentiel (passer d’un référentiel héliocentrique à un référentiel géocentrique, un truc du genre). Pour rédiger la suite je me suis beaucoup aidé du bouquin « le minimum théorique » de Leonard Susskind (pas toujours évident à piger du premier coup mais super intéressant, j’ai utilisé son bouquin sur la mécanique classique) et aussi des cours de physique disponibles sur youtube de Richard Taillet (mécanique, semestre 2, cour 3), très clair et très bien expliqué où à partir des équations du mouvement il démontre la trajectoire elliptique et les lois de Kepler entre 2 corps. Bon j’espère ne pas avoir glissé trop de conneries dans le résumé de toutes ces étapes.
(Avec le schéma ci-dessus, on voit bien le long de l’année le décalage entre le soleil moyen où la Terre tourne théoriquement autour en faisant un cercle parfait, et le soleil vrai)
1) Des trucs de mécanique classique
Un système physique peut-être résumé en mécanique comme la somme des énergies cinétiques (Ec) et potentielles (Ep) qui lui sont attribuées, c’est l’énergie totale du système (Et). L’énergie cinétique représente en gros « l’énergie du mouvement » de l’objet étudié, et l’énergie potentielle, comme son nom l’indique, l’énergie que l’objet pourrait potentiellement libérer (pas terrible comme définition mais j’ai du mal à le cerner autrement). Par exemple si on prend une balle en haut d’un immeuble en suspens, prête à être lâchée, alors à ce moment-là son énergie potentielle sera à son maximum, et son énergie cinétique sera nulle (car la balle est immobile par rapport au référentiel immeuble). Maintenant si on prend cette balle juste avant son impact au sol, son énergie cinétique sera alors à son maximum (la balle aura atteint sa vitesse max) mais cette fois son énergie potentielle sera presque au minimum (elle sera au minimum quand la balle aura touché le sol).
Donc en formule de physique l’énergie totale d’un système ça donne ça :
Et=Ec+Ep=1/2 mv^2 + V(x), avec V(x)=potentiel du système. Je l’ai noté V(x) car le potentiel dépend de la position de l’objet étudié dans un repère donné (en reprenant l’exemple du ballon sur le gratte-ciel, plus le gratte-ciel sera élevé et plus l’énergie potentielle du ballon sera forte c’est l’idée en gros).
Et bien à partir de tout ça on peut retrouver les équations du mouvement de l’objet. Mais avant d’aller plus loin on va définir d’autres trucs de physique (mais pas trop faut pas déconner non plus rassurez-vous).
a) L’énergie potentielle
Pour les systèmes à force centrale (comme les planètes soumises à l’influence gravitationnelle d’un astre, que l’on apparentera à un point) on peut définir que les sommes des forces appliquées à l’objet sont égales à la négative du gradient de l’énergie potentielle : ∑F=-grad(V), il y a un moins devant grad car l’objet est dirigé vers le point (donc l’accélération symbolisable par un vecteur serait dirigée vers le point si on schématisait l’ensemble). On peut aussi définir la force de la façon suivante :
Fi(x)=-∂V(x)/∂xi ; ce truc signifie que la force exprimée sur un degré de liberté spatial du système (ici xi) est égale à la dérivée partielle du potentiel par rapport à ce degré de liberté spatial…Enfin je crois. On peut aussi dire qu’une force c’est la divergence spatiale d’une énergie potentielle (en backflip mikado la plupart du temps mais bref passons ce détail).
D’après les lois de Newton la somme des forces est égale au produit d’une masse par l’accélération de cet objet. Donc ∑F=ma. Ca explique pourquoi lorsque l’accélération d’un objet est nulle (objet immobile ou en vitesse constante), alors la somme des forces qui lui sont appliquées est égale à 0. Une force c’est une masse accélérée.
b) Dérivées, intégrales, dérivées partielles
Les dérivées, dérivées partielles
Pour l’énergie potentielle on a parlé de gradient, mais c’est quoi en fait ? He bien il s’agit simplement de la somme des dérivées partielles spatiales du potentiel V ; c’est-à-dire :
Grad (V(x))= ∂(Vx)/∂x+∂(Vy)/∂y+∂(Vz)/∂z
La dérivée d’une fonction par rapport au temps indique son taux de variation dans le temps (on va alors parler de vélocité, c’est-à-dire de vitesse de l’objet selon une orientation du repère choisit, cartésien par exemple) mais ça peut aussi se faire dans l’espace si la fonction est dérivée par rapport à l’espace. En fait on peut très bien dériver une fonction avec n’importe laquelle de ses paramètres (pour les fonctions à plusieurs variables), pas juste le temps.
La dérivée seconde d’une fonction indique le taux de variation de la dérivée première. Si la dérivée première est la vélocité, alors la dérivée seconde ce sera l’accélération de l’objet selon un des axes du repère.
En général les dérivées permettent de voir comment va évoluer une fonction (croissante, décroissante, stationnaire…) et les dérivées secondes permettent de trouver les maximums et les minimums locaux de la fonction, entre autre.
Les dérivées ne sont pas exclusivement réservées aux fonctions à une variable, elles peuvent être aussi utilisées pour les fonctions dépendant de plusieurs variables ; on va alors parler de dérivées partielles. Le principe reste quasiment le même sauf que quand on dérive la fonction par rapport à l’un des paramètres, on considère les autres comme de simples coefficients fixes. Par exemple on envisage la fonction F(x ;y)=3x+2y. Si on fait ∂F(x ;y)/∂x ça donne =3, et si on fait ∂F(x ;y)/∂y on obtient =2.
Les intégrales
C’est un peu la démarche inverse d’une dérivée, si on peut dire ça comme ça. Si on devait définir de façon un peu plus rigoureuse ce truc là on pourrait dire que c’est la limite d’une somme d’aires placées sous une fonction. On peut donc en déduire que le potentiel est égal à la négative d’une primitive d’une force plus une constante : V=-∫Fdx+constante. Par contre ici on laissera tomber la constante (voir le principe d’invariance de jauge pour les curieux). Donc ça donne V=-∫Fdx.
c) Le Lagrangien
En physique, le Lagrangien permet de déterminer l’évolution du système dans le temps et l’espace, déduire les équations du mouvement, et repérer les symétries éventuelles, c’est un peu un couteau suisse quoi…Il est aussi indispensable pour déterminer l’action d’un système (voir le principe de moindre action pour les curieux).
Le Lagrangien : c’est simplement l’énergie cinétique moins l’énergie potentielle de l’objet étudié (en tout cas pour nos planètes, mais c’est pas toujours le cas pour tous les systèmes), donc ça donne : L=1/2 mv^2-V(x). Le Lagrangien peut être considéré comme une fonction dépendant de 2 variables, une variable d’espace (induite par l’énergie potentielle) et une variable de vitesse (induite par l’énergie cinétique). Cela nous fait donc L=L(xi ; dxi/dt). (Dx/dt=vélocité sur axe x et xi symbolise les axes x, y et z).
Une symétrie : En physique c’est quand on a une invariance du lagrangien lorsque l’objet se déplace dans tel ou tel degré de liberté du système (on parle ici d’espace des configurations avec trois degrés de liberté dans l’espace, x, y et z). Par exemple la conservation du moment angulaire est une symétrie par rotation du système. On a donc dL/dt=0 dans une symétrie du Lagrangien liée au temps.
d) Les équations d’Euler-Lagrange
Elles nous permettent, avec l’apport du Lagrangien, de trouver le moment conjugué du système (il va nous servir pour détecter des symétries du système) et les équations du mouvement.
Moment conjugué : c’est la dérivée du Lagrangien par rapport à la vélocité.
Equation d’Euler-Lagrange : c’est simplement : (d/dt)( dL/dVx’) – (dL/dx)=0 (pour un seul degré de liberté, ici x. x’ est la dérivée de x).
2) Trouver les équations du mouvement d’un astre autour du Soleil.
a) Le Lagrangien en coordonnées polaires
On va d’abord chercher à définir le Lagrangien du système dans un repère orthonormé (x, y, z), puis on va le modifier pour fonctionner dans un repère en coordonnées polaires(r et ө, avec r=rayon, c’est-à-dire la distance entre les 2 astres et ө=angle).
L’énergie cinétique : c’est simple, c’est Ec=1/2 m(dx/dt)^2+1/2 m(dy/dt)^2. On considère que l’objet se déplace dans un plan unique (x, y) donc on néglige z. Si on avait intégré z on aurait parlé de coordonnées polaires cylindriques.
L’énergie potentielle : on va faire un petit tour de passe-passe ; on sait presque tous que la force gravitationnelle entre 2 corps définie par Newton est égale à GMm/r^2 (proportionnelle au produit des masses et inversement proportionnelle au carré de leur distance d’éloignement). Or on a vu que V=-∫fdx ; donc si on intègre GMm/r^2 on va obtenir finalement V(r)=-GMm/r (car le potentiel dépend de la distance r qui est un paramètre variable, G, M et m sont considérés comme fixes, souvenez-vous de l’exemple du gratte-ciel et du ballon).
On sait que le Lagrangien est la différence entre l’énergie cinétique et l’énergie potentielle, donc :
L=Ec-Ep=1/2 m(dx/dt)^2+1/2 m(dy/dt)^2+GMm/r
Maintenant on va convertir notre Lagrangien en coordonnées polaires. C’est plus pratique pour étudier un objet en rotation autour d’un autre. Il va y avoir 2 degrés de liberté : r qui est la distance entre les 2 astres et ө qui représentera en degrés l’angle entre le périastre et la position de l’objet en rotation par rapport au foyer (le Soleil).
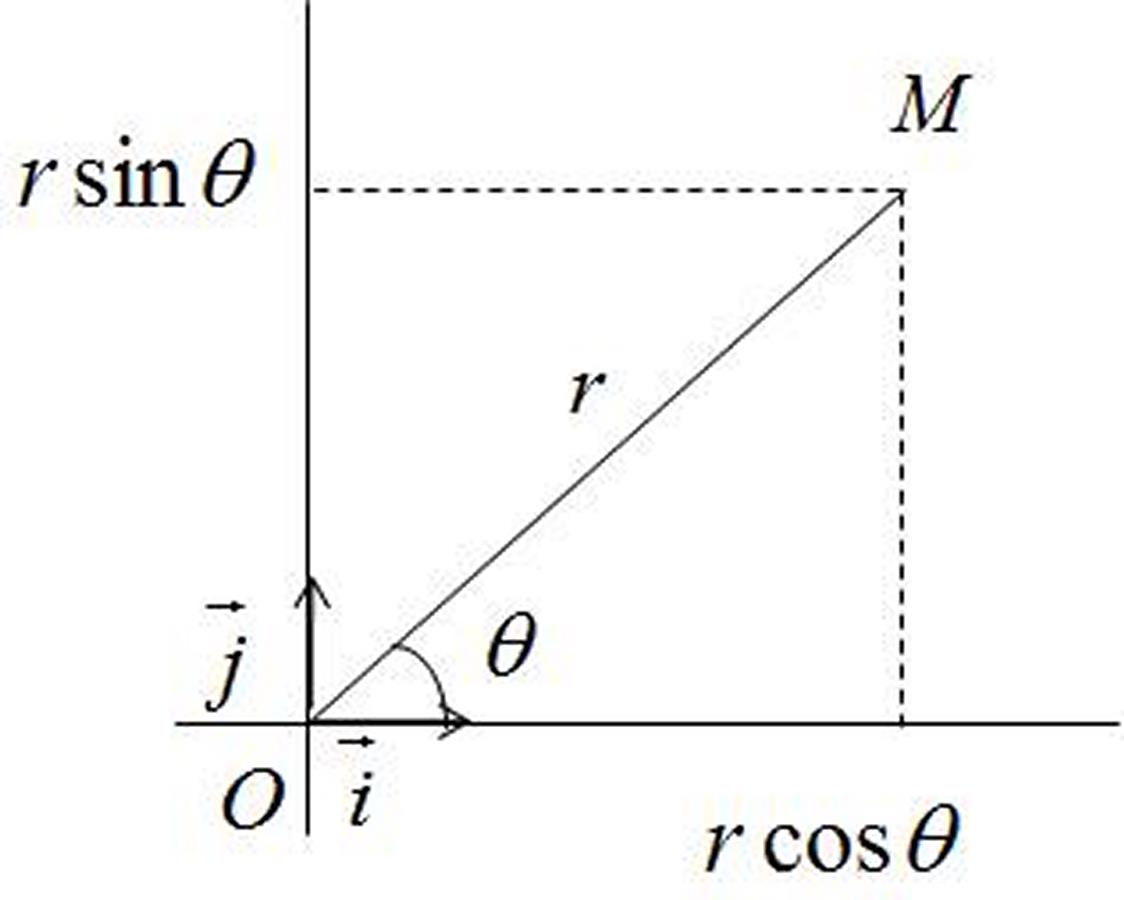
D’après le petit schéma on peut donc convertir les coordonnées cartésiennes en coordonnées polaires de la façon suivante :
X=rcos(ө)
Y=rsin(ө)
Il suffit ensuite simplement de remplacer dans notre lagrangien ces nouvelles données ; cependant dans le Lagrangien on parle de vélocité alors qu’ici nous n’avons que des positions. Avant de trafiquer le Lagrangien il va donc être nécessaire de calculer les dérivées premières de X et Y. En prenant en compte le fait que ce sont des produits de fonctions (r avec cos(ө) et r avec sin(ө)), et que ө est à considérer comme une fonction dépendant du temps (donc cos(ө) et sin(ө) sont également à envisager comme des fonctions composées dans notre calcul de dérivées), on va trouver ça :
X’=r’cos(ө)-sin(ө)ө’r (les’ ça veut dire dérivée temporelle, c’est pour écrire plus vite et moins galérer. Par exemple r’ est la dérivée temporelle de r).
Y’=r’sin(ө)+ө’cos(ө)r
Si on prend nos dérivées et qu’on les fourre dans le Lagrangien à la place des coordonnées du début, on obtient :
L=1/2 m(r’^2+ө’^2r^2)+GMm/r, soit notre Lagrangien du système en coordonnées polaires.
b) Les équations du mouvement
Cette fois on va sortir de notre boîte à outils et dégainer les équations d’Euler-Lagrange. On va l’utiliser pour nos 2 degrés de liberté et ça va nous donner :
(d/dt)( dL/dr’)- (dL/dr)=0 et (d/dt)(dL/dө’)-(dL/dө)=0
Quand on les résouds, on obtient donc 2 équations au total :
r’’=rө’^2-GM/r^2 (r’’ est la dérivée seconde temporelle de r, l’accélération quoi).
(d/dt) (mө’r^2)=0 (cette équation indique une symétrie du système, c’est-à-dire l’invariance du Lagrangien par rapport à la vitesse angulaire par rapport au temps. Autrement dit cela exprime la conservation du moment cinétique de l’objet quand il tourne autour du Soleil). On pourrait aussi écrire cette seconde équation sous cette forme : mө’r^2=constante.
Comme on sait que m est une masse considérée comme constante, alors on peut donc affiner et dire que r^2ө’=constante=C.
c) Obtenir une fonction du type r(ө)
Cette fonction va nous permettre de déterminer la trajectoire d’un astre selon ses coordonnées polaires. Pour ça, reprenons le Lagrangien établis avant :
L= 1/2 m (r’^2+ө’^2r^2) + GMm/r
Nous avons établis également que C=r^2ө’. Cette constante n’est autre que la constante des aires, soit l’une des trois règles des lois de Kepler. Bon alors maintenant on va intégrer cette constante dans l’équation du Lagrangien et ça donne ça :
1/2 r’^2+(1/2) (C^2/r^2)=GM/r+constante (on remarque qu’en simplifiant l’écriture m a disparu, soit la masse de l’objet en mouvement. Donc on peut en déduire que la masse de l’objet n’influe pas sur son déplacement autour de l’objet principal).
Maintenant on va chercher à transformer notre Lagrangien sous la forme d’une fonction r(ө).
Il va alors falloir établir r’ comme une fonction dépendant du paramètre ө, sachant que ө dépend du temps t ; on va poser mathématiquement :
r’=dr/dt=(dr/dө) (dө/dt) ; r’ se définit ici comme une fonction composée.
Donc en fait ça donne également dr(ө(t))/dt=(dr/dө)( dө/dt), donc au final ө’(dr/dө).
A partir de ça on remodifie l’écriture de la fonction trouvée précédemment et on obtient :
On remarque alors que l’équation peut être simplifiée, et ça nous donne :
(d^2 u/dө^2) + u=GM/C^2 , ça va nous permettre de calculer u selon ө donc r selon ө.
Bref là on a une équation différentielle à résoudre…Pas gagné cette histoire. Si u est constante on a comme solution d’après l’équation GM/C^2, mais ça reste une solution particulière (ça c’est si la trajectoire de l’objet décrit un cercle dans l’espace, pas une ellipse). La solution ça va être l’oscillateur harmonique de la forme suivante Acos(ө) + Bsin(ө), égal aussi à Xcos(ө+ө0) avec X l’amplitude du mouvement. On retrouve aussi l’oscillateur harmonique dans l’étude des mouvements du pendule ou l’électricité par exemple. En fait on peut donc en déduire que :
u(ө) = GM/C^2 + Xcos(ө+ө0) ; et maintenant c’est bien gentil tout ça, mais nous on cherche r(ө) quand même merde ! Ha bin oui alors comme r=1/u, alors bon voilà :
u(ө)=GM/C^2 (1+ (AC^2/GM) cos (ө+ө0)) , – AC^2/GM c’est l’excentricité de l’ellipse notée e.
Donc : r(ө)= (C^2/GM)/(1-e cos(ө+ө0)). Le ө0 est négligeable(il est utile si on veut décaler la période de la fonction c’est tout) donc on obtient notre équation recherchée :
r(ө)=(C^2/GM)/(1- e cos(ө))
Si e est égal ou supérieur à 0 mais strictement inférieur à 1, alors on a une trajectoire en ellipse; si e=1 alors notre trajectoire va être parabolique, et enfin si e>1 alors on va avoir une hyperbole. Cette équation permet de tracer la trajectoire selon l’angle de rotation, mais comment tracer cette trajectoire par rapport au temps ? En fait on va faire le lien de façon d’abord géométrique, et ensuite par approximation en utilisant des suites de nombres.
Petit apparté sur l’oscillateur harmonique : à partir de l’oscillateur harmonique, solution de l’équation différentielle vue auparavant, on peut exprimer différemment l’équation de la trajectoire. En effet, cet oscillateur résous l’équation différentielle suivante :
x’’+ Wo^2x=0 , comme on peut le voir elle ressemble beaucoup à celle trouvée précédemment : (d^2 u/dө^2) + u=GM/C^2.
En fait l’équation de l’oscillateur décrit un système physique au cour du temps avec absence d’amortissement, frottements, au voisinage d’une position d’équilibre stable. Wo est un paramètre appelé la pulsation propre, il est égal à Wo=2π/To, To est la période propre du phénomène.
Comme on l’a vu la solution peut s’écrire x(t)=Acos(Wot) et y(t)=Bsin(Wot) (ce sont des coordonnées paramétriques), en fait A=xo (position de x à l’instant t=0) et B=Vo/Wo (vitesse initiale divisée par la pulsation). Pourquoi ? car quand on pose t=0 alors x(0)=A (car cos(0)=1 et sin(0)=0) et quand on dérive y(t) et x(t) par rapport au temps, on trouve y’(t)=WoBcos(Wot), et si on fait y’(o) on obtient y’(o)=WoB donc B=y’(o)/Wo (y’(o)=Vo).
(En tapant sur google « oscillateur harmonique sans amortissement planètes », on tombe sur ce pdf très bien expliqué ci-dessus)
3) La trajectoire elliptique
P=C^2/(GM), c’est ce qu’on appelle le paramètre de l’ellipse, donc r=P/(1- e cos(ө)).
Pour calculer r max, soit la distance à l’aphélie il suffit de poser ө=0, on obtient donc r max=P/(1-e), et la distance au périhélie il suffit de poser ө=180° ce qui nous donne r min=P/(1+e). Ensuite pour obtenir le demi-diamètre de notre ellipse il suffit de poser l’opération (r min + r max)/2 qui est égal à a= P/(1-e)^2. Donc si ө=90°, c’est-à-dire si cos (ө)=0, alors P=a (1- e)^2. Pour définir géométriquement l’ensemble des paramètres de l’ellipse j’ai introduit un petit schéma pour être plus clair :
C=ae et b=a√(1-e^2). F c’est le foyer du Soleil (l’astre immobile servant d’origine), e l’excentricité et a le demi grand axe de l’ellipse. C c’est la distance du foyer jusqu’au centre o de l’ellipse.
4) L’équation du temps
C’est l’équation qui permet de déterminer la vitesse réelle du Soleil autour de la Terre (quand on prend la Terre comme référentiel). D’après wikipédia elle se compose de l’équation du centre additionnée à l’équation de l’obliquité de la Terre. Il existe également sur wikipépé une version simplifiée de l’équation où on a construit une fonction en approximant le phénomène par le biais de fonctions trigonométriques, mais nous on va regarder plutôt la version complète, œuf, jambon, et fromage.
a) L’équation du centre
Elle est ici rédigée sous la forme d’une fonction C dépendant de l’anomalie moyenne M, soit C(M). L’anomalie moyenne est simple à définir, c’est la vitesse angulaire moyenne de l’astre qui bouge (on peut également considérer que c’est la vitesse de l’objet si sa trajectoire était parfaitement circulaire, en fait c’est la distance parcourue par l’objet en une rotation divisée par le temps mis à faire cette rotation, c’est tout). Donc M est à envisager aussi comme une fonction dépendant du temps t cette fois (donc on peut considérer la fonction C comme une fonction composée puisque C dépend de M qui dépend de t, en fait C dépend indirectement de t).
Il existe l’équation de Kepler qui relie l’anomalie moyenne et l’anomalie excentrique : E-e sin(E)=M, avec M anomalie moyenne et E anomalie excentrique. En revanche l’équation ne contient pas l’anomalie vraie v. L’anomalie vraie dépend du temps, mais sur le schéma il n’y a pas de lien géométrique entre l’anomalie moyenne et les autres. Par contre l’équation précédente la relie à l’anomalie excentrique, mais problème : si on connaît l’anomalie moyenne (donc le temps…) on ne peut pas résoudre l’équation de Kepler de façon analytique, il va donc falloir approximer un résultat, trouver une solution approchée pour déterminer une position de l’astre par rapport au temps (et merde…).
Pour effectuer cette approximation on va utiliser des séries, et selon l’excentricité de la trajectoire on va employer :
. Pour une trajectoire d’excentricité avec e>e0=0.6627… Alors on va utiliser une série de Fourier (ici, c’est pour le cas d’objets avec de très fortes excentricités comme les comètes par exemple).
. Pour une trajectoire d’excentricité avec e<e0=0.6627… Alors on va utiliser une série entière (pour les planètes utiles à la navigation ce sera des séries entières donc, tout comme pour la Terre).
b) L’équation de l’obliquité de la Terre
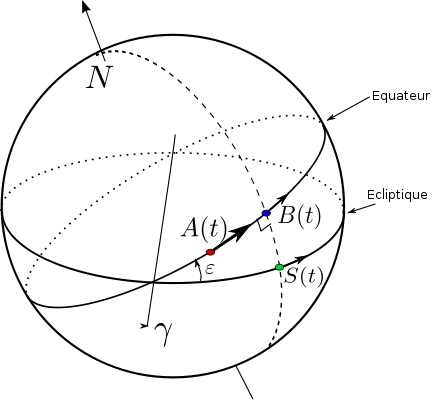
C’est une fonction qui dépend de la longitude écliptique LE donc on peut l’écrire R(LE). Elle permet de transvaser les coordonnées écliptiques du Soleil en coordonnées équatoriales, plus utiles à l’usage. Calculer LE est facile, c’est simplement la vitesse angulaire moyenne du Soleil autour de la Terre (référentiel géocentrique) avec en plus C(M) qui permet de corriger cette vitesse selon la forme elliptique de la trajectoire. R(LE) utilise une formule pour faire le lien entre longitude écliptique et coordonnées équatoriales (voir schéma suivant).
Dans le schéma ci-dessus, ϒ représente le point vernal (croisement de l’équateur et de l’écliptique au nœud ascendant) ; ϵ c’est l’angle d’inclinaison entre l’équateur et l’écliptique qui varie légèrement sur une longue période. A(t) est un point quelconque dépendant du temps t, et fixe sur la surface terrestre donc il fait un tour en un jour sidéral de façon régulière. Le point S(t) est aligné entre le centre de la Terre et le Soleil, et fait un tour en une année sidérale, donc il a une vitesse irrégulière sur un an (trajectoire elliptique). Et B(t) est l’interception entre le méridien de S(t) et l’équateur. On obtient donc à la surface terrestre un triangle rectangle sphérique rectangle en B(t), ce qui donne cos(ϵ)=ϒB(t)/ϒS(t), donc ϒB(t)=cos(ϵ) ϒS(t). Jusqu’ici ça va après ça se complique un peu. Alors pour résumer, A(t) tourne de façon régulière, S(t) de façon irrégulière donc B(t) également, donc en fait A(t) est relié à l’anomalie moyenne et B(t) est relié à l’anomalie vraie…On peut en déduire que l’angle entre A(t) et B(t) est l’heure solaire vraie. Donc Hv(t)=angle BA= angle Bϒ+angleϒA.
Pour définir l’heure solaire moyenne, on va prendre le point A(t) car il se meut de façon régulière, et on va prendre un point fictif dérivé de S(t) qu’on va appeler Sv(t) ; mais celui-là on va imaginer qu’il bouge de façon régulière. Ca donne : Hm(t)=angleSvϒ+angleϒA. Comme l’équation du temps c’est la différence entre l’heure solaire moyenne et l’heure solaire vraie, alors E(t)=Hm(t)-Hv(t)=angleBϒ-angleSvϒ.
Mais on sait que ϒB(t)=cos(ϵ) ϒS(t), or ϒB(t)=tan(ϒB) et ϒS(t)=tan(ϒS), donc :
Tan(angleϒSv+E)=cos(ϵ) tan(angleϒS)
E(t)=-angleϒSv+arctan(cos(ϵ)tan(angleϒS))
En utilisant une série et en posant y=tan(ϵ/2) pour ϵ/2≈0,20, ça donne :
R= arctan (cos (ϵ) tan(ϒs))-ϒs
R= arctan (cos(ϵ) tan (λs-π))-(λs-π)
R= -arctan ((sin(2λs) y^2)/(1+y^2cos(2λs)))
R=-y^2sin (2λs) + ½ y^4sin(4λs)-1/3 y^6 sin (6λs)+….
Voilà, avec tout ça on peut faire un petit programme de positionnement avec le Soleil, et aussi peut-être avec les planètes utiles à la nav, avec la difficulté du changement de référentiel en plus. Pour la Lune c’est plus compliqué car elle est soumise à beaucoup de contraintes et effectue des mouvements plus complexes (problème à trois corps), plus nombreux en un temps plus court.
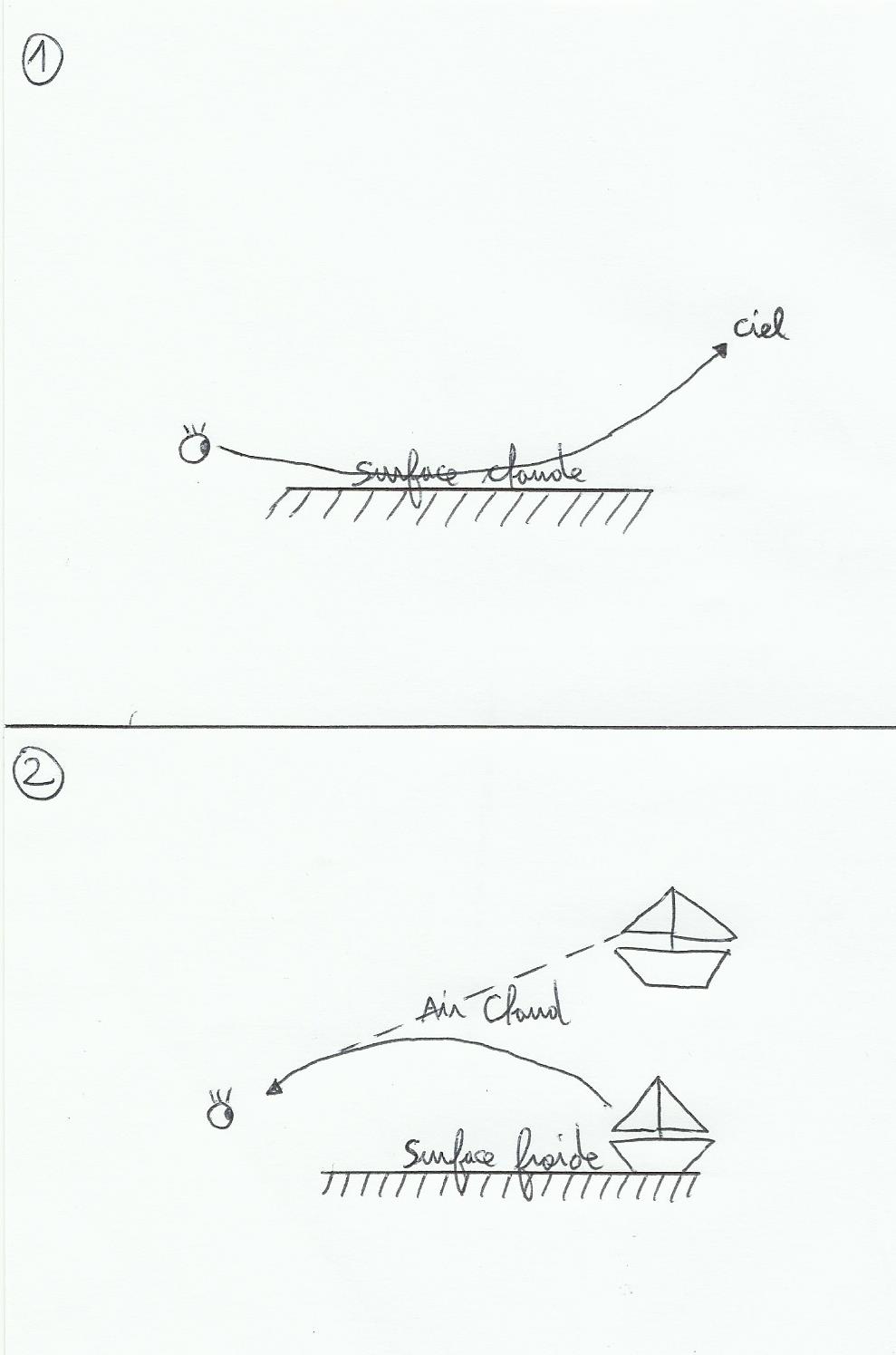
Une couscoussière designée par les daft punk ? La maquette bidon d’un ovni de série Z ? à première vue ça ressemble à pas grand chose, mais ce bidule peut générer un peu de jus… En utilisant les différences de chaleur, soit l’effet Seebeck (pour faire bien).
En traînant un peu sur youtube on peut trouver des vidéos appelées « incroyables expériences », elles sont vraiment très intéressantes; on y apprend à faire une bobine Tesla, un chargeur portable, des piles, comment fonctionne l’induction… Et en fouillant on trouve la vidéo « thermopile ». Sur cette vidéo tout est expliqué, l’effet Seebeck, Peltier, la construction et le fonctionnement d’un module Peltier, la vidéo est avant tout une démo de l’effet Seebeck, mais la thermopile présentée et employée ne résiste pas à plus d’un usage (la lampe à huile crame les composants internes du module Peltier assez vite). Ce petit tuto propose un bricolage permettant un emploi éventuel à long terme de cet effet.
1) Effet Peltier, effet Seebeck
L’effet Peltier(ou effet thermoélectrique)est un phénomène physique capable de provoquer un déplacement de chaleur grâce au passage d’un courant électrique; pour cela on fait circuler le courant à travers deux matériaux conducteurs différents reliés entre eux par des jonctions, au fur et à mesure une jonction va refroidir et l’autre se réchauffer. On emploie ce principe dans la réfrigération. Certains couples de métaux seront plus efficaces que d’autres, un peu comme les réactions d’oxydoréductions, on parle de thermocouples.
L’effet Seebeck c’est un peu l’inverse tout simplement, c’est l’effet qui va nous intéresser.
2) Le module Peltier
A la base ce composant est conçu pour générer une différence de température à partir d’un courant continu, le type de module utilisé ici (12706) fonctionne sur du 12 volts. On l’utilise pour plusieurs choses, notamment le refroidissement de microprocesseurs, des petites glacières de voitures…Et aussi les tireuses à bière. Il a deux faces, l’une froide et l’autre chaude, l’objet à refroidir se place sur la face froide et on installe un système d’évacuation de la chaleur sur l’autre côté(comme dans la vidéo « incroyables expériences ») comme un petit ventilateur par exemple.
Cependant même si il n’est pas spécifiquement conçu pour ça si on applique une source chaude sur la face chaude du module et une source froide sur la face froide, il va se créer une différence de potentiel entre ses deux bornes, donc passage de courant. Le rendement reste cependant très faible. Si on pose le module sur une table avec un voltmètre branché dessus, et que l’on pose juste sa main sur l’autre face on va voir la présence d’un léger courant électrique qui va décroître au fur et à mesure (rapidement la différence de température entre les deux faces va s’équilibrer). Après on peut s’amuser en faisant varier les sources froides ou chaudes: un sèche-cheveux, une loupe, des glaçons…On obtient évidemment de meilleurs résultats en utilisant une source froide et une source chaude en même temps, si ce n’est pas le cas à plus ou moins long terme les températures entre les deux faces du module finiront par s’équilibrer, la tension générée finira donc par chuter.
3) Ingrédients et coûts du bidule
La thermopile que l’on va bricoler devra répondre à un cahier des charges minimum : ne pas coûter trop cher (parce que quand même faut pas déconner) et fonctionner à partir d’une ou plusieurs sources d’énergie facilement utilisables, et employer une source chaude ne dépassant pas les 100°C maximum afin de ne pas endommager les modules Peltier.
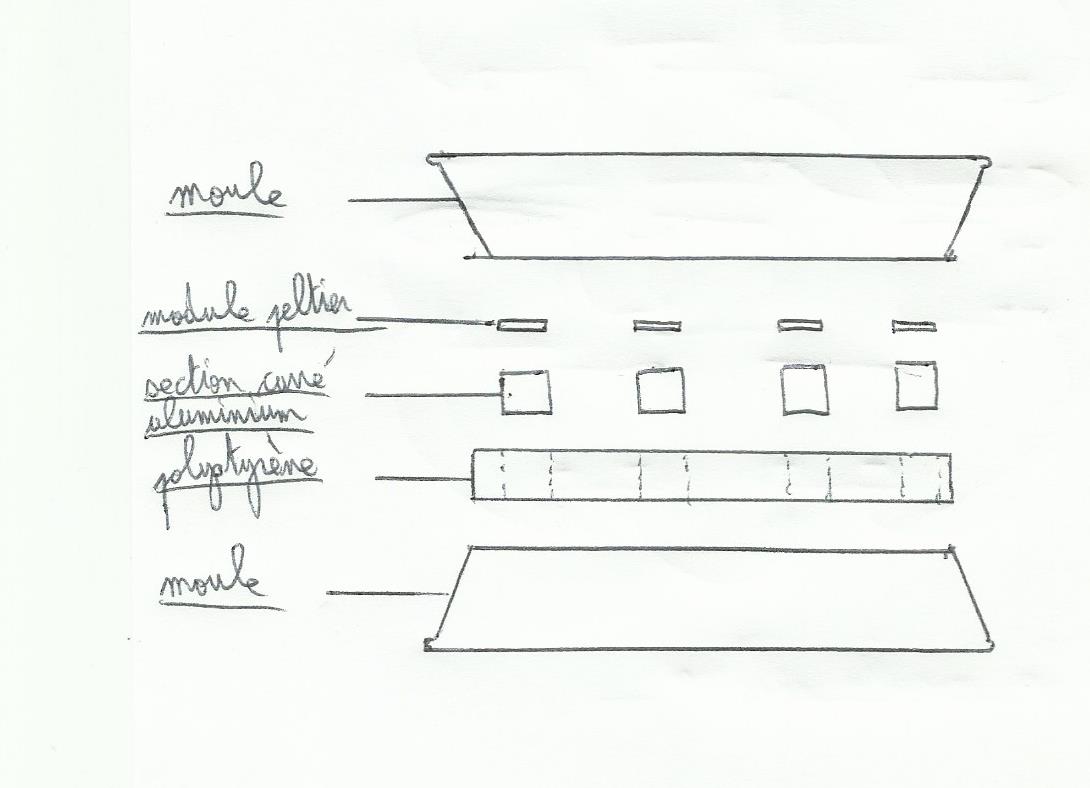
Pour la fabriquer on va avoir besoin de plusieurs éléments :
Deux moules à gâteaux en aluminium
Un tube creux de section carrée aluminium
Une couverture de survie
Un booster qui permet d’augmenter la tension d’entrée à 5 volts en sortie tout en la stabilisant(modèle CE8301).
Il va aussi nous falloir une plaque de polystyrène (aussi épaisse que le côté de la section alu du tube), du silicone en tube, une plaque de pvc transparent (et résistant aux UV) , des petits miroirs et un système de support pour les utiliser (des charnières de porte dans mon cas). Il va falloir aussi 10 modules Peltier, et si possible de la pâte thermique en tube. On ajoutera à tout ça des serviettes éponge.
En tout, si on fait de la récup pour environ 25 euros on peut la faire. Sur internet dix modules coûtent environ vingt euros, le booster moins de trois euros. Après si on a du bol on peut peut-être aussi récupérer des modules Peltier à droite à gauche dans des pc nazes, vieilles glacières ou encore mieux des bars en démontant discrètement la tireuse, après avoir délicatement saoulé le tenancier.
4) Le bricolage
On commence par décaper la peinture au cul des deux moules pour mettre l’aluminium à vif, sur l’un des deux on décape également le fond du moule jusqu’à l’aluminium; ce dernier sera la « partie froide » de la thermopile, et du coup le premier moule qui a juste le cul poncé sera la « partie chaude »(c’est mieux de garder le fond du moule noir pour la partie chaude afin de bien capter les rayons du soleil, donc la chaleur).
On découpe le tube alu en section carrée. Un module Peltier est de forme carrée avec des côtés à quatre cm. Par chance j’ai trouvé un tube de section deux sur deux cm, il m’a donc fallu découper vingt morceaux de tube (deux pour chaque module), un morceau est long de quatre cm. Le tube que j’avais était anodisé, du coup je l’ai décapé pour enlever la pellicule anodisée afin d’optimiser la conduction de chaleur.
On découpe la plaque de polystyrène en cercle de diamètre semblable au cul des moules, puis dans ce cercle on va découper dix carrés de quatre cm de côté. Ils vont accueillir chacun deux morceaux de tube alu juxtaposés. Cette plaque va jouer le rôle d’isolant entre les deux moules.
On peut ensuite coller avec du silicone (avec de la colle cyanocrylate ça fait fondre le polystyrène) le disque polystyrène sur le moule « face chaude » et disposer les morceau d’alu dans les trous sans les coller au moule.
On peut alors placer les modules Peltier sur les carrés alu obtenus pour les brancher et les souder en série:
Avant de les fixer aux morceaux d’alu, on met de la pâte thermique sur l’alu (pas trop, deux ou trois filets fin feront l’affaire) et de la colle forte en petite quantité aux quatre coins de chaque module. Avant de coller l’ensemble surtout bien faire gaffe à l’orientation des faces des modules par rapport aux « parties chaudes et parties froides », c’est pas mal de tester au multimètre avant.
Avant de coller le moule « partie froide » on remet de la pâte thermique sur la face restée libre des modules Peltier, puis on colle le moule avec du silicone.
Pour finir le collage on silicone les jonctions pour étanchéifier l’ensemble.
Maintenant que la partie principale de la pile est assemblée, on va isoler les deux moules; sur le pourtour du moule « chaud » on va coller un isolant si possible hydrophobe, pour ma part j’ai découpé un bout de tapis d’exercices au sol (bonne excuse pour plus m’en servir après c’est cool) puis on colle dessus un morceau de couverture de survie, face dorée vers l’extérieur. Sur le pourtour du moule « froid » on colle des morceaux de tissus éponge. Par dessus on mettra un morceau de couverture de survie mais cette fois la partie argentée sera tournée vers l’extérieur.
5) Fonctionnement
a. Avec le soleil:
Sans isolation, le montage comme sur la photo, par temps presque complètement ensoleillé monte maximum à 1,1 volts pour 20 mA au bout de 15 minutes environ, puis redescend et s’équilibre à 0.8 volts environ. On utilise le même principe que l’effet de chaleur dans une véranda ou une voiture (effet de serre). La couleur noire du moule capte plus facilement la chaleur, et le pvc transparent « emprisonne » les rayonnements infrarouges, conservant plus de chaleur dans le moule. Pour améliorer la tension obtenue il va donc falloir obligatoirement isoler les moules et essayer de capter encore plus de lumière pour la diriger à l’intérieur.
Le moule « partie chaude »
Le moule « partie froide »:
Sur la dernière photo, on ajoute des miroirs fixés sur des petites charnières pliées à 90 degrés. Pour maintenir les charnières dans la position voulue, on peut les maintenir avec des morceaux de cintres:
Au résultat final on obtient ça:
Une fois notre couscoussière customisée, on obtient les résultats suivants (temps ensoleillé d’août normand):
+10 min=1.12 V; +20 min=1.6 V; +20 min=1.8 V; +30 min= 1.7 V (stabilisation ensuite à 1.6 V). 45 minutes plus tard si on vaporise la partie froide avec de l’eau tiède la tension monte à 2.6 V. En vaporisant davantage on peut monter jusqu’à 3.7 V. 15 minutes après la tension est revenue à 1.6 V pour 50 mA environ. A 3.7 V de tension on a 80 mA. Quand on vaporise la tension monte rapidement, chute et se stabilise un peu à 2 V (70 mA) pour retomber finalement à 1.6 V. En imbibant d’eau les morceaux de tissus éponge d’eau il ne se passe pas grand chose, mieux vaut vaporiser directement la partie froide dans le fond du moule « partie froide ».
b) avec de la vapeur d’eau bouillante
On place la couscoussière partie chaude vers le bas, sur une casserole d’eau bouillante avec un couvercle en aluminium dessus. il ne doit pas y avoir de contact direct entre le couvercle alu et le moule « partie chaude » (pour ne pas trop faire chauffer les modules Peltier par conduction de chaleur), on peut utiliser des morceaux de cartons par exemple. La vapeur d’eau va chauffer la partie chaude. On obtient:
début: augmente direct et se stabilise à 2.8 V; +5min=2.65 V et 90mA; +10min=2.55V et 85mA; +15min=2.47 V et 83mA; +20min=2.3 V et 75mA.
Si maintenant on ajoute de l’eau fraîche dans le moule de la partie froide, on a alors:
début: 7.5 V pour 2.5 A; +5min=8V et 2.5 A; +10min=7.5 V et 2.5V; +15min=6.85V et 2.2A; +20min=6.55V et 2.2A.(la puissance fournie diminue car l’eau ajoutée se réchauffe petit à petit).
Maintenant, on va voir si on peut utiliser l’énergie obtenue pour recharger un portable ou des piles AA, pour cela on va brancher en sortie du générateur le booster (DC-DC 0.9V-5V). D’après les données fabricant, en lui fournissant une tension d’entrée comprise entre 0.9V et 5V, il libère un courant stable de 5V environ. Il y a sur le circuit une diode rouge qui indique si la charge se fait.
A partir d’environ 1.12 V mon téléphone se met en charge, cependant après vérification sur le long terme la charge obtenue fonctionne mal; en effet bien qu’il s’affiche en recharge sur son écran ça semble plus décharger l’accu qu’autre chose. La charge du téléphone semble correcte quand la tension à l’entrée du booster fait au moins 2.6 V et 80 mA (ma batterie de téléphone est une batterie 3.7 V et 800 mah).
Dans le commerce j’ai trouvé un chargeur de piles AA en prise usb. On peut charger ses piles via une prise usb d’ordinateur ou une prise allume cigare 12 V, et on peut l’utiliser pour recharger un portable avec. En branchant le chargeur en sortie du booster il ne se passe rien (la led rouge témoin du chargeur ne s’allume pas), aussi bien avec le soleil que la vapeur d’eau chaude (sur le chargeur il est noté que pour fonctionner correctement il doit recevoir une tension de 5 V et une intensité de 0.5 A).
Pour améliorer le système il va falloir d’une part augmenter significativement l’isolation pour limiter au max les pertes thermiques, et d’autre part trouver un moyen plus efficace de capter les rayons du soleil, un peu comme les fours solaires fait maison. Concernant la source d’énergie solaire la principale difficulté va être de traiter un courant de sortie faible pour le rendre exploitable (l’ajout d’un composant crée une perte énergétique par effet joule…), même si on l’emploie juste pour recharger une seule pile AA rechargeable (1.2V 2100 mah). Pour la source de vapeur d’eau chaude il va falloir trouver un moyen de stabiliser la tension à 5 V, et peut-être aussi diminuer l’intensité fournie pour ne pas bousiller le chargeur ou les piles. On pourra aussi améliorer la partie froide du bidule en la modifiant en réservoir à eau. Peut-être y a t il aussi d’autres sources de chaleur exploitables pour la pile…(réactions chimiques exothermique avec de la chaux vive par exemple, à voir)
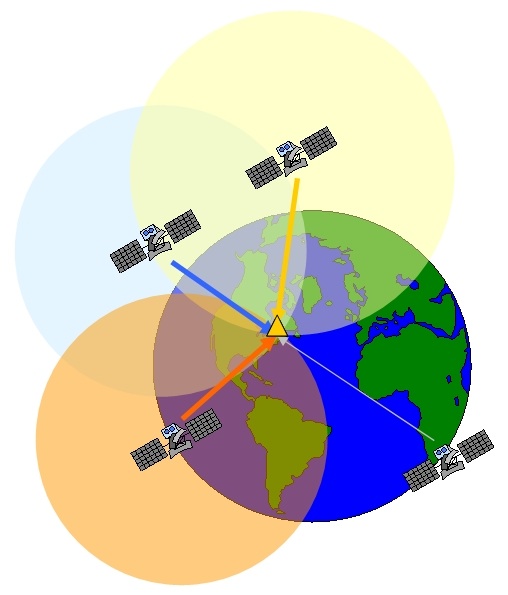
Plutôt facile d’utilisation(on appuie sur un bouton et hop ayé c ‘est bâché on a sa position), le principe de fonctionnement du gps est plus difficile à saisir, en gros il va utiliser le temps comme mesure pour déterminer des distances(entre nous et les satellites appropriés)et par recoupement de ces distances(un peu comme un point à 3 relèvements)il va afficher notre latitude et longitude. Actuellement le nombre de satellites utilisés pour ce système dépasse les 24, et ils orbitent autour de la terre à environ 11000 milles. Il y en a autant pour être sûr que au moins trois soient visibles en tout point de la terre en même temps. On va voir aussi que le gps fait intervenir les lois de la relativité restreinte et générale d’Einstein pour obtenir une très bonne précision, non non c’est pas des conneries!
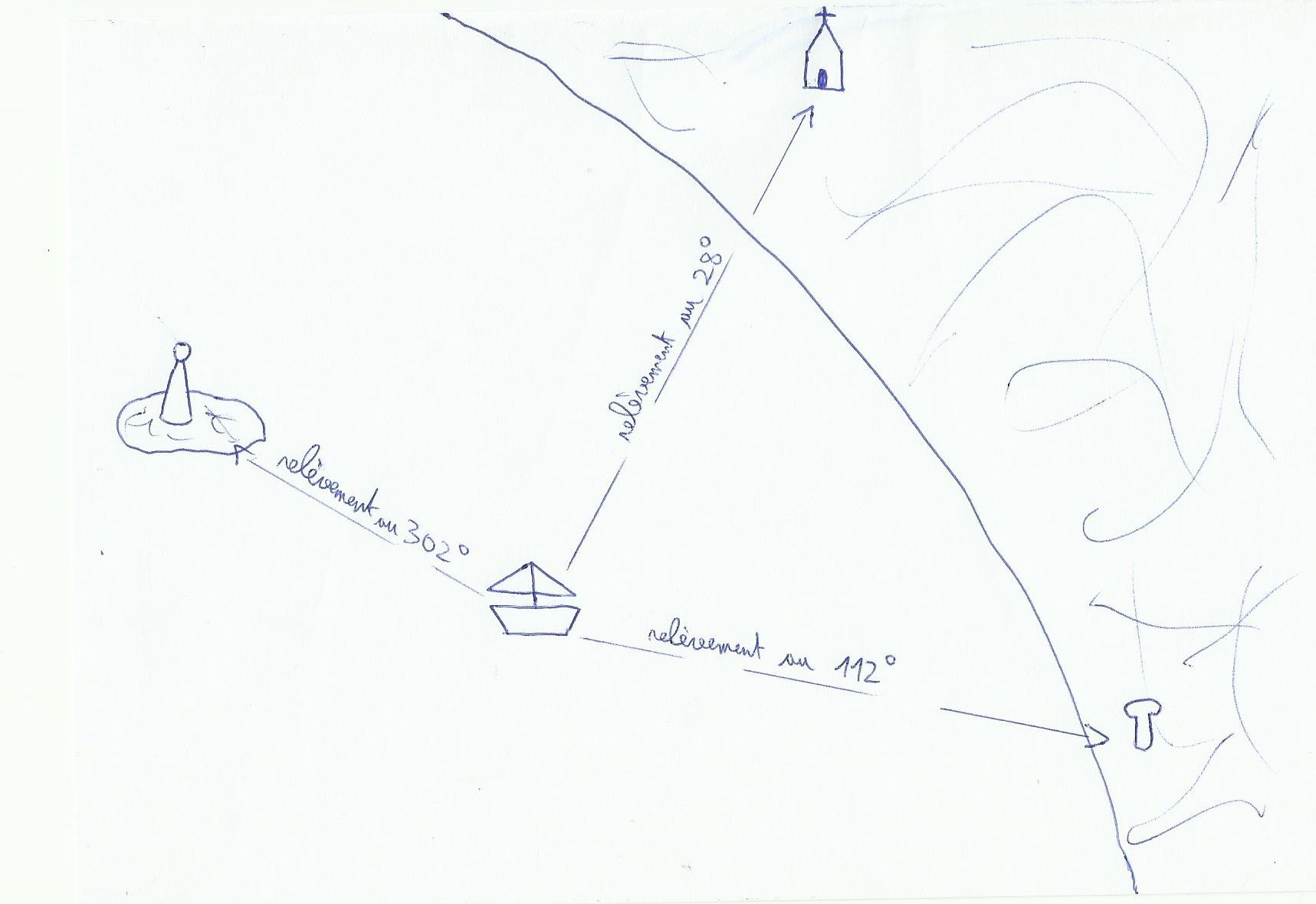
1) Un point à trois relèvements en 3 dimensions
En navigation côtière lorsque l’on fait un point à trois relèvement et qu’on le trace sur la carte, on travaille dans un plan en deux dimensions.
Pour le positionnement avec le gps c’est pareil sauf que là on travaillera en 3D. Le relèvement d’un satellite ne nous situera pas sur une droite mais sur une sphère dont le centre sera le satellite. Le recoupement de ces trois sphères indique deux positions, une sur terre et une autre à l’extérieur qui du coup ne sera pas gardée. Le relèvement compas nous donne un angle et le relèvement du satellite nous donne une distance.
Sur ce schéma on remarque la présence d’un quatrième satellite, tiens c’est vrai qu’est-ce qu’il fout là celui là ?
La mesure de la distance entre nous et le satellite est le produit de la vitesse de la lumière(vitesse du signal, 300000 km/s environ dans le vide)avec le temps de réception du signal, donc pour avoir une mesure précise de cette distance il faut que l’horloge interne des satellites et du récepteur soient d’une part synchro et en plus extrêmement précises. Si un satellite envoie un signal au temps 1 et que le gps le reçoit au temps 2, le temps de trajet et donc la distance ne peut être connu que si les horloges sont synchro, si elles ne le sont pas le temps de trajet est faussé et du coup la distance calculée est faussée aussi.
Pour obtenir une précision à la nanoseconde les satellites sont équipés d’horloges atomiques internes, et elles sont toutes synchro entre elles. Problème: une horloge atomique coûtant la peau des fesses, un bras, les yeux de la tête et une bonne blinde on ne pouvait en équiper tout les gps. On a donc trouvé une parade, on l’étalonne par rapport aux horloges des satellites grâce à un quatrième satellite. Si l’horloge du gps est bien réglée, la sphère de positionnement du quatrième satellite doit couper les autres au même endroit(le petit triangle sur le schéma). Si ce n’est pas le cas, le gps corrige le temps de son horloge pour que ça coincide, dingue non ? en fait le gps donne non seulement un point précis mais aussi le temps avec une précision atomique car il règle son temps en permanence avec celui des satellites, équipés d’horloges atomiques.
2) Tout est relatif…
Comme on vient de le voir le principe du gps se base sur la mesure du temps de parcours de signaux électroniques se déplaçant à la vitesse de la lumière, il est donc important que les horloges sur terre et celles des satellites soient synchro, or l’emploi d’un quatrième satellite n’est pas suffisant…car le temps local du récepteur(le gps) et des satellites n’évoluera pas de la même façon à cause notamment de la grande différence de vitesse entre les deux, bref c’est le bordel.
a. La relativité restreinte
En gros son principe remet en cause la notion de temps absolu. Auparavant on croyait que le temps s’écoulait de la même façon et à la même vitesse partout dans l’univers et pour tout le monde, et que la vitesse de la lumière était infinie. En fait c’est la vitesse de la lumière qui est une notion absolue et finie, le temps est relatif à son sujet selon sa vitesse par rapport à la vitesse de la lumière. Le paradoxe des jumeaux(appelé aussi paradoxe des horloges)illustre bien le problème. On prend deux jumeaux, on en met un dans un vaisseau spatial capable de se déplacer à un vitesse proche de la lumière, et l’autre reste sur terre. Si le premier part acheter du pain sur Osiris (une exoplanète)en navette spatiale, il va revenir plus jeune que celui resté sur terre! Pour comprendre le phénomène les plus courageux pourront s’intéresser aux équations de Lorentz, bien expliquées dans le bouquin « la relativité » d’Einstein, sinon en allant sur youtube il y a un épisode de la quatrième dimension qui illustre ce principe. Cela n’est valable que quand les différences de vitesses sont proches de la lumière, on ne vas pas vieillir plus lentement en faisant du 300 à l’heure sur l’autoroute! On risque même le contraire là…
Un satellite gps se déplace à environ 14000 km/heure, donc sa vitesse est non négligeable par rapport à celle de la lumière…
Petite équation simple pour se rendre compte du phénomène:
S=√(1-v²/c²)
S est le facteur de contraction, il indique le changement relatif du temps et de l’espace dans un objet à la vitesse v. Pour notre navette spatiale qui roule à 150000 km/s ça donne:
S=√(1-150000²/300000²)=0.87, le temps dans la navette évoluera à 87% du temps de référence(la terre), donc le temps dans la navette se déroulera 13% moins vite que celui de la terre.
Pour notre satellite qui se déplace bien vite par rapport à notre récepteur gps cela créer un décalage infime mais non négligeable de 8 microsecondes par jour de retard par rapport à notre temps.
b. La relativité générale
Tout le monde connaît l’effet Doppler, particulièrement les gendarmes qui en on fait leur fond de commerce… immobile dans la rue, si une moto se rapproche de nous son bruit de moteur va monter dans les aigus, et quand elle s’éloigne de nous ça bascule dans les graves.
Si on connait la vitesse du son dans l’air(environ 340m/s)on peut alors calculer la vitesse du véhicule. Et bien cet effet marche aussi avec la lumière! et comme la vitesse de la lumière est liée au temps…C’est la zone!
Dans notre cas on vas alors parler d’effet Doppler gravitationnel(pour le placer en soirée où à table celui là c’est chaud), explication: la lumière peut se présenter sous la forme d’un transfert d’informations via les photons, particules n’ayant pas de masse donc capable d’atteindre dans le vide la vitesse maximale de 300000 km/s. Mais même sans masse les photons sont déviés par la gravité, et la gravité est équivalente à une accélération. De plus la lumière est à la fois une onde(comme le son…)et un mouvement de particules. Conclusion: un champ de gravité accélère les photons et augmente les fréquences de la lumière. En gros la fréquence de la lumière sera augmentée quand le satellite enverra son signal vers nous, et elle sera ralentie quand le signal ira de bas en haut à cause de la gravité. En fait le champ gravitationnel plus fort sur terre ralenti la lumière et donc le temps par rapport au champ gravitationnel du satellite.
Ce principe de relativité générale provoque un décalage de 46 microsecondes par jour entre notre temps local et celui du satellite(46 microsecondes en moins pour nous donc).
Le gps doit donc corriger par jour un décalage de 38 microsecondes environ, sinon il perdraitchaque jours 12 km de précision!(299792458 m/s multiplié par ces 38 microsecondes donne presque 12 km) Malgré sa simplicité d’utilisation, le gps utilise finalement des concepts complexes.
A la recherche du salon annuel de la charentaise à Tripaille-en-Paumé, de renommée plutôt locale, vous réalisez avec une stupeur effrayante une erreur sur votre itinéraire. Au lieu d’emprunter la sortie d’autoroute A234 en direction de la zone indus de Létron-la-Trine, vous avez bifurqué trop tôt en prenant le chemin du siège social de l’amicale de sculpture sur boîtes à camembert au carrefour de Bermudaille-en-Paté… Waaah la tuile! Impossible de se situer sur la carte! Bon y a peut-être moyen au moins de définir sa latitude… Sinon on peut aussi allumer le gps ou demander son chemin se sera quand même plus efficace!
1) Le soleil, un bâton, un truc pour mesurer…Et le bon moment
On pense souvent que la découverte de la Terre ronde comme un ballon de foot est attribuée à Christophe Colomb, en fait la réalité est un peu plus complexe. Ce dernier a prouvé cela de façon empirique avec ses voyages, mais il a démontré une théorie déjà évoquée depuis longtemps. Plusieurs siècles plus tôt(5ème siècle avant JC)Platon considérait déjà la Terre comme sphérique. En effet les Grecs avaient déjà noté le caractère courbe de la surface terrestre(un bateau faisant cap sur l’horizon voit d’abord sa coque disparaître, puis le bas de son mât, et enfin le reste). Mais au 2ème siècle avant JC un grec a réussi grâce à une méthode très simple à calculer la circonférence de notre ballon de foot, avec une précision assez incroyable pour l’époque(700 km de différence seulement avec notre valeur actuelle!)c’est Eratosthène.
Son raisonnement était le suivant: comme la terre est courbe, alors les rayons du soleil atteignent la surface terrestre avec des angles différents. Il a ajouté à ça un peu de trigonométrie pour assaisonner et c’est tout.
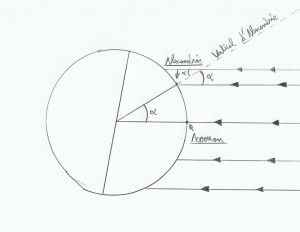
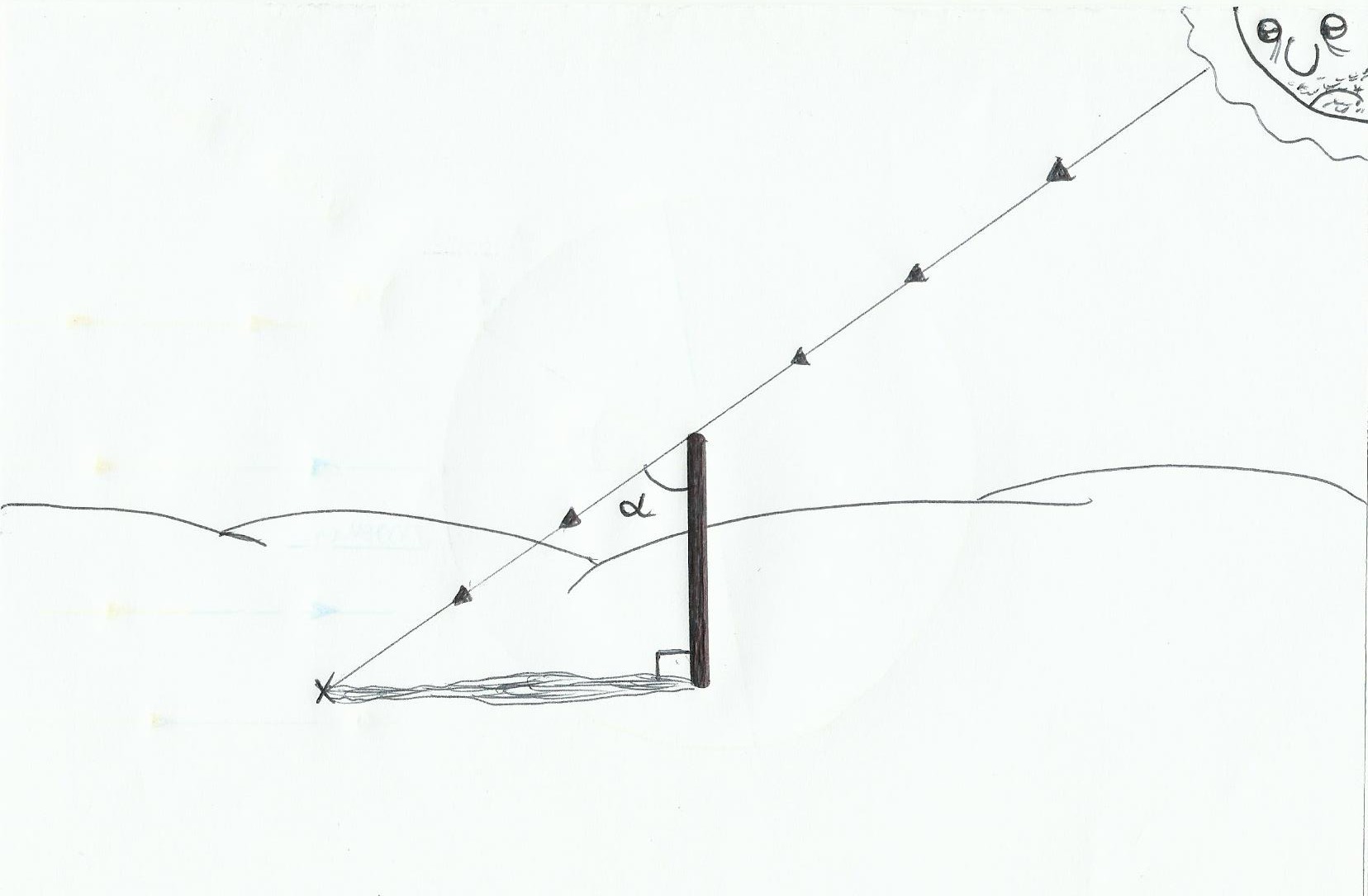
Pour son calcul il considérait les rayons du Soleil parallèles entre eux(car cet astre par rapport à la Terre est bien plus volumineux et surtout très éloigné). A l’époque il savait que lors du 21 juin(solstice d’été), à midi local à Assouan les silhouettes verticales ne dessinaient pas d’ombre, il a donc déduit qu’à ce moment là le Soleil se situait sur la droite perpendiculaire à la tangente passant par Assouan. Après tout ça il est facile de deviner la distance angulaire entre Assouan et Alexandrie(angla alpha sur le schéma), en plantant un bâton à Alexandrie et en observant son ombre à midi local le 21 juin, on trouve alpha.
Il faut planter le bâton le plus droit possible(utiliser un fil à plomb)pour avoir une mesure la plus précise possible(pour être encore plus précis, utiliser de préférence un bâton grand et fin, et un sol bien plane). En connaissant la taille de notre bâton et en mesurant l’ombre on peut rapidement retrouver alpha avec un peu de trigo(l’ensemble forme un triangle rectangle). En effet Tan(alpha)=côté opposé/côté adjacent donc Tan(alpha)=ombre/bâton. Eratosthène a trouvé un angle alpha égal à 7, 2° environ.
Comme il connaissait la distance entre les deux villes, et que 7, 2° équivaut à 1/50ème de 360°(soit la circonférence totale de la Terre)il a alors multiplié la distance entre les deux villes par 50 ce qui donna 39350 km(la valeur réelle approximative est de 40033 km).
Bon vous allez dire c’est bien gentil tout ça mais pour aller à Tripaille-en-Paumé on est pas plus avancé là! Oui c’est sûr, mais en prenant le problème d’une autre façon on peut trouver sa latitude, à peu près en tout cas…
En connaissant la règle des quatre 21(voir article « la sphère céleste »)on sait environ la position du pied de l’astre du Soleil aux solstices(+ou-23°26′) et aux équinoxes(0°)en latitude. Donc si dans ce cas on veut connaître la latitude d’Alexandrie il suffit d’additionner l’angle alpha à la latitude d’Assouan. Assouan a une latitude d’environ 24°(logique puisqu’au solstice d’été, le 21 juin le pied de l’astre Solaire a une latitude de 23°26′, or à cette date il n’y a pas d’ombre pour les silhouettes verticales à Assouan)donc Alexandrie a une latitude de 31° à peu près.
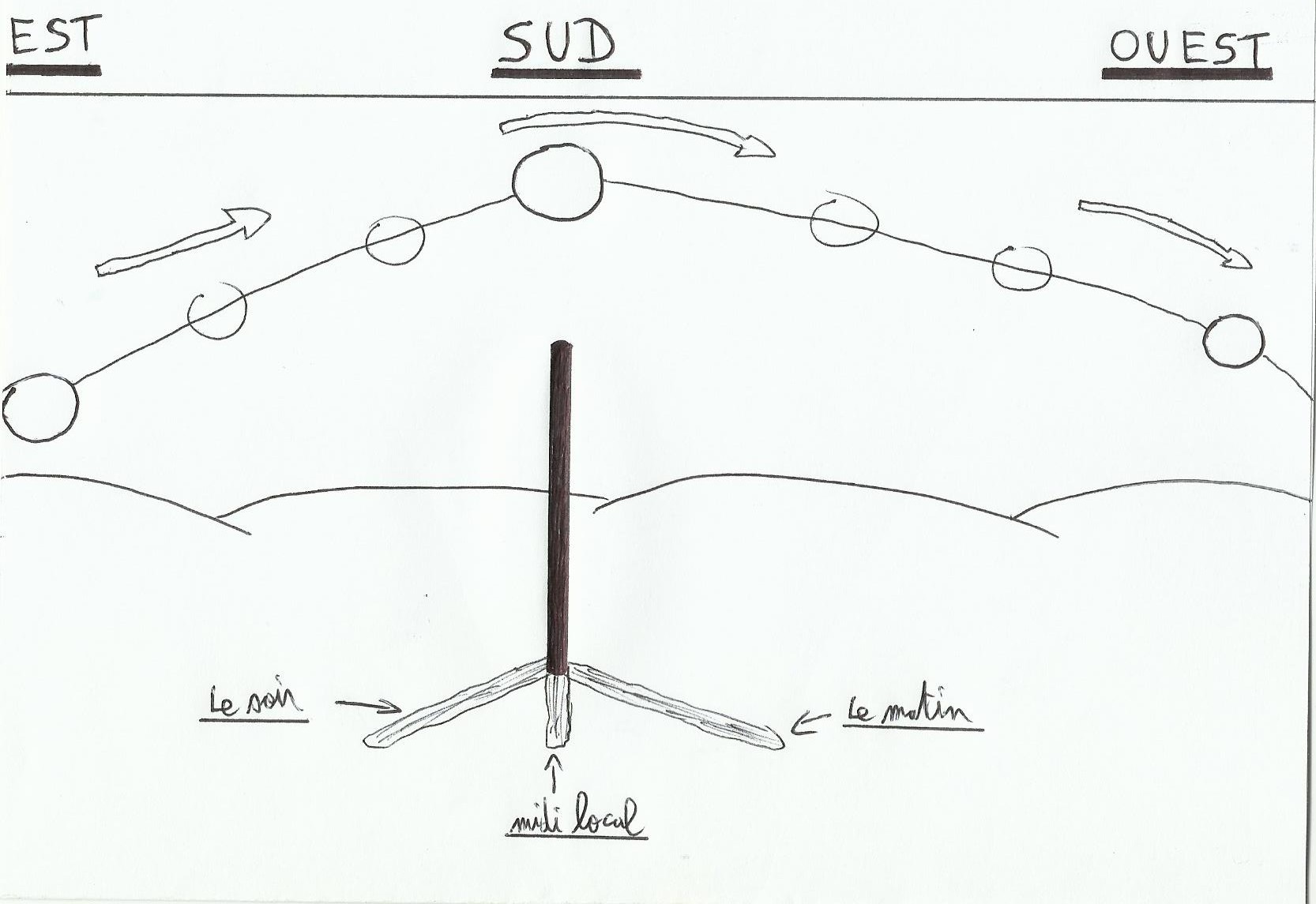
Maintenant dans notre cas si nous sommes perdu le 22 septembre et que nous calculons alpha à midi local(pour trouver le midi local avec le bâton, c’est le moment où ce dernier dessinera sur le sol l’ombre la plus courte dans la journée, car à ce moment là le soleil sera le plus haut sur l’horizon), si alpha est égal à 51° cela veut dire que notre latitude est de 51°(car le jour de l’équinoxe d’automne la latitude du pied de l’astre Soleil=0° à midi local environ). Après pour avoir la position en latitude du pied de l’astre Soleil à l’année il faut trimballer les éphémérides dans la boîte à gants mais bon là…
Remarque: si on arrive à définir l’heure précise du midi local de notre lieu(grâce à l’ombre du bâton qui rétrécit jusqu’à midi local puis qui réaugmente ensuite), et que notre montre est pile réglée à l’heure UT, et que par miracle on a à disposition les éphémérides dans la boîte à gants alors on pourra trouver aussi approximativement notre longitude.
Pour trouver notre midi local avec précision, on va faire un peu la même méthode employée pour la méridienne(voir article « La Méridienne »). Comme le soleil reste à son zénith un certain temps, difficile de trouver le temps exact du midi local en mesurant juste la taille de l’ombre quand elle semble être la plus réduite. En fait on va prendre une mesure de l’ombre quand le soleil est orienté sud-est (en notant l’heure à ce moment là) avec un fil tendu partant de la base du bâton, et on trace au sol un arc de cercle(de rayon égal à cette mesure). Quand l’ombre recoupe notre tracé(le soleil va se rapprocher de l’ouest) on note aussitôt l’heure; l’heure du midi local est alors la somme de ces deux heures divisée par deux.
Dans les éphémérides, on retrouve l’heure de passage du soleil au méridien de Greenwich(le midi local de Greenwich). Donc si notre montre est en heure UT précise, que l’on a réussit à définir notre midi local alors on trouvera notre longitude. Le soleil évolue autour de la Terre(dans notre référentiel bien sûr!)au rythme de 15° par heure environ(cette vitesse est de toute façon indiquée de façon plus précise dans les éphémérides), donc notre longitude=(heure midilocal-heure midi local Greenwich)*15.
2) Le pendule du professeur Tournesol
Dans l’article « Coriolis », on a vu que plus l’on s’approchait des pôles et plus Coriolis avait tendance à dévier les corps en mouvement sur de longues distances(vent et courant)vers la droite dans l’hémisphère nord et la gauche dans l’hémisphère sud. Inversement plus l’on s’approche de l’équateur et plus cette « force » s’annule. Donc garé sur le parking de l’église entre Brignolle-la-Farfouillette et Létron-la-Trine, on est en droit de se demander si il n’existe pas un lien ou une formule entre Coriolis et le changement de latitude…Quand on s’ennuie faut bien s’occuper!
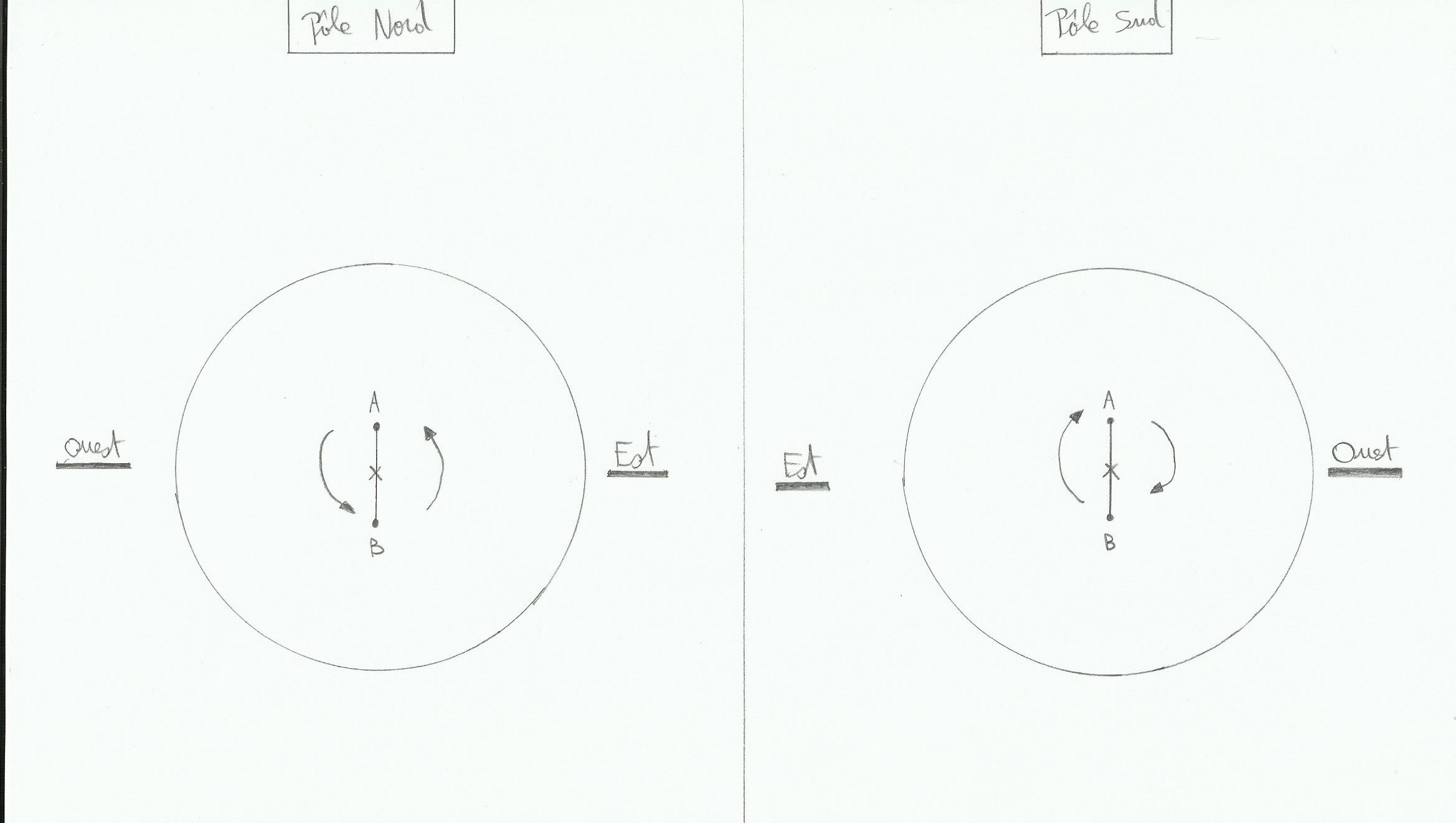
On peut effectivement trouver un lien par le biais du pendule de Foucault, son principe fonctionne un peu comme un gyroscope. En gros lorsque l’on fait osciller un pendule(on considère les forces de frottement nulles, le mouvement d’oscillation continue indéfiniment), son plan d’oscillation va rester fixe par rapport à la rotation de la terre sur elle-même, en fait c’est le plan sous le pendule qui va tourner par rapport à lui. Il est facile de déduire la vitesse de rotation du plan du pendule si il est situé pile sur l’un des deux pôles:
On vas dire que le pendule oscille entre A et B. Si le pendule se situe pile sur le pôle Nord alors le plan sous le pendule va tourner à la vitesse de 15° par heure environ dans le sens anti-horaire(car la terre tourne sur elle-même en 24 heures donc 360°/24 heures, et le soleil se couche à l’Ouest). Au pôle Sud se sera la même vitesse mais dans le sens horaire, et à l’équateur comme Coriolis est nulle le plan sera fixe par rapport au plan d’oscillation du pendule. Mais alors à Brignolle-la-Farfouillette, comment ça se passe? En fait cela crée un mouvement apparent du pendule dans le sens opposé(pôle Nord, le pendule tourne en sens horaire et au pôle sud en sens anti-horaire).
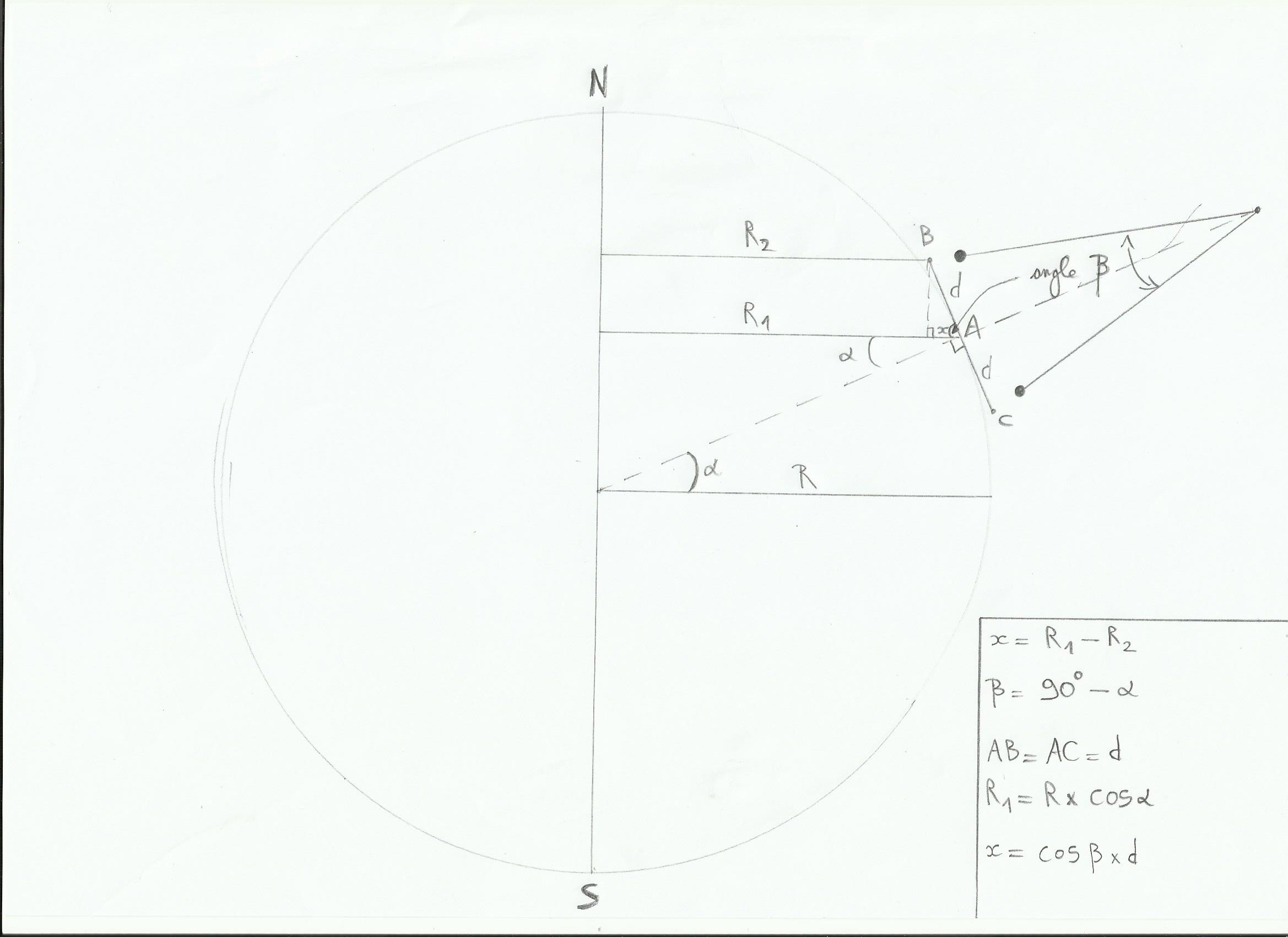
Et puis la vitesse de rotation va dépendre de la latitude du pendule, grâce à la différence de vitesse linéaire selon la latitude. Sur le schéma suivant les points B, A et C sont situés à des latitudes différentes, leur vitesse angulaire terrestre est la même(360° en 24 heures), mais pas leur vitesse linéaire(car la circonférence de la Terre diminue quand la latitude augmente, du coup le point aura moins de chemin à parcourir en 24 heures, donc sa vitesse linéaire sera plus lente si sa latitude augmente. Sur ce schéma le centre du pendule est A et il oscille entre B et C; la latitude de A est l’angle alpha et R le rayon de la Terre:
La vitesse linéaire de A est égale à la vitesse angulaire de la Terre(w) multipliée par R1 donc Va=w*R1; R1=cos(alpha)*R. Du coup Va=w*cos(alpha)*R.
Vb=w*R2, et R2=R1-x. x=cos(bêta)*d d’après la trigo, or l’angle bêta=90°-alpha donc cos(90°-alpha)=sin(alpha). x=sin(alpha)*d. Donc R2=cos(alpha)*R-sin(alpha)*d, Vb=w*(cos(alpha)*R-sin(alpha)*d)
Avec un raisonnement analogue on trouve Vc=w*(cos(alpha)*R+sin(alpha)*d)
Au final on remarque que Vc>Va>Vb, et entre chacune de ces vitesses la différence est de w*sin(alpha)*d. Cette différence entre les vitesses va créer le mouvement apparent du plan sous le pendule. On peut en déduire que la vitesse angulaire de ce plan est de w*sin(alpha), autrement dit la vitesse de rotation angulaire de la Terre multipliée par le sinus de la latitude(on enlève d qui est la largeur du plan, indépendante de la vitesse angulaire). Pour conclure on peut écrire cette équation:
angle de rotation par heure=15*sin(latitude)
(Remarque: aux pôles avec une latitude de 90° on retrouve le principe énoncé au-dessus, tout comme avec une latitude de 0° à l’équateur.)
3) Rappel
La hauteur de l’étoile polaire sur l’horizon donne aussi notre latitude(article « se positionner sans gps ni calculatrice »). Après je n’ai pas encore essayé mais sachant que Mintaka(constellation d’Orion) est quasiment située sur l’équateur céleste, peut-être que sa hauteur sur l’horizon moins 90° donne notre latitude…à voir. Sinon pour retrouver son chemin on peut aussi demander sa position au premier piéton croisé, ça ira plus vite!
Un après midi de toussaint pluvieux, alors que la télévision ne capte que derrick et que vous venez de recevoir vos factures, attention l’ennui et la déprime guette…mais tiens donc qu’est-ce que je peut faire? vider le frigo? compter les dalles de carrelage dans la salle de bain? apprendre l’annuaire par cœur pour le délire? organiser un tournoi de mikado avec mon chien? Bof… Ha ba non je peut faire une boussole au fait! Comme ça je saurai enfin si la porte de mes toilettes est exposée nord, sud… Depuis le temps que je me posait cette question fatidique, c’est merveilleux tout ça!
1) Matos nécessaire
On prend une aiguille à coudre, un bol ou une assiette creuse, un aimant, un petit bout de carton fin, une pile de 4,5 volts style grosse pile carrée dans les vieilles lampes torche, et si on a ça sous la main un peu de fil de cuivre émaillé(on en trouve dans les vieux postes radio par exemple, c’est du fil de cuivre avec un vernis isolant dessus).
2) Comment ça se passe
Tout d’abord on remplit le bol de flotte(avec un liquide moins dense comme l’huile ça marche mieux mais bon de l’eau c’est bien), puis on prend l’aiguille et l’aimant. On va ensuite frotter l’aiguille avec l’aimant mais toujours dans le même sens(pas de va et vient, on frotte de bas en haut, de bas en haut…)pendant 5 minutes puis on dépose l’aiguille sur le morceau de carton, et le carton sur l’eau au milieu du bol. Au bout d’un moment l’aiguille va arrêter de tourner et se stabiliser dans l’axe nord/sud(très efficace pour draguer en boîte de nuit).
En frottant cette aiguille dans le sens tête/pointe, le côté piquant de l’aiguille indique le sud.
On peut aussi magnétiser l’aiguille en l’enroulant avec du fil de cuivre vernis, puis on connecte les 2 extrémités du fil avec les bornes de la pile(ne pas oublier de poncer le vernis aux extrémités du fil pour que ça fonctionne, si la pile chauffe après un petit délais alors ça marche)enfin bref avec un aimant c’est plus simple pour le même résultat.
3) Avec un aimant néodyme
Le truc le plus efficace est l’utilisation d’un aimant néodyme à la place de l’aiguille. Très rapidement il va se mettre dans l’axe nord/sud.
L’aimant néodyme est tellement puissant que l’on peut même se passer du bol d’eau, en le maintenant en équilibre sur l’ongle du pouce il va tourner et se mettre dans l’axe nord/sud tout seul(Gérard Majax peut aller se rhabiller!).
(Remarque: Si on applique cette méthode et que l’on peut en même temps voir l’étoile polaire, on peut approximativement trouver la déclinaison de l’endroit où nous sommes sans gps ni compas, bon d’accord ça sert pas à grand chose mais au moins ça occupe la soirée…)
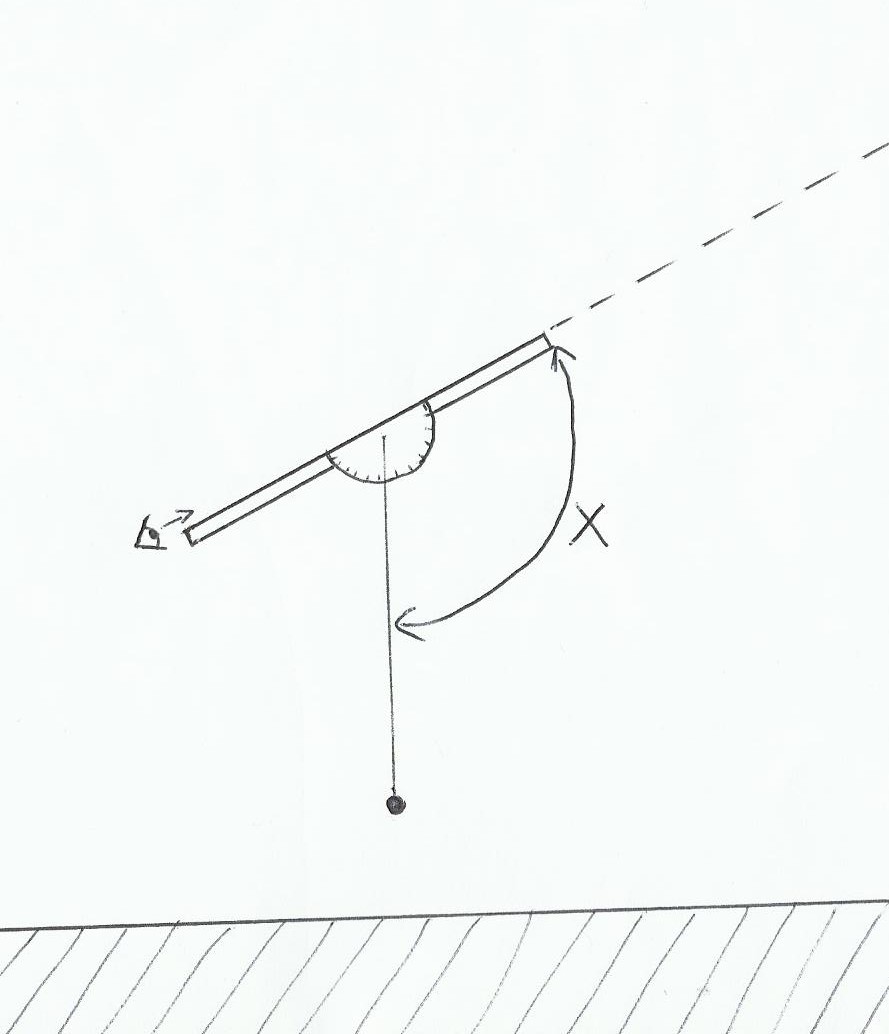
Pour s’initier à la navigation astronomique, on pense qu’il est indispensable d’acheter un sextant. Le premier prix pour cet instrument est le mark 3 qui coûte une soixantaine d’euros. Pour avoir des mesures plus précises de sa position, le tarif devient par la suite rapidement exponentiel…et inversement proportionnel à la motivation d’apprendre qui peut vite décliner. C’est vrai, pourquoi s’embêter à dépenser de l’argent et faire des calculs alors qu’avec le même prix on peut s’offrir un gps de bonne qualité? La petite méthode suivante permet non seulement de ne pas débourser plus de dix euros, mais en plus elle permet de mesurer des hauteurs d’étoiles sans avoir besoin de pouvoir distinguer l’horizon.
1)Matériel
Il suffit d’avoir sous la main un simple rapporteur en plastique, un fil long (un mètre, un mètre cinquante)et fin, un truc qui fait lest(un ou plusieurs gros écrous par exemple)et un morceau de bois ou de plastique long, bien droit et de section carrée. Un petit tube de colle forte nous permettra de coller le rapporteur et la pièce en bois ou plastique de la façon suivante:
Il faut bien faire attention à coller le bord droit du rapporteur bien parallèle au morceau de bois.
Ensuite on fait passer le fil dans le petit trou central du rapporteur, on fait un nœud d’arrêt tout bête et au bout du fil on attache le lest(pour la photo j’ai mis une clé, tant qu’il y a un peu de poids le reste n’a pas d’importance).
Ayé finit! On l’utilise de la façon suivante:
Plus le bout de bois est long, droit, et plus le fil est fin et le lest lourd, plus on gagne en précision. On peut aussi installer l’ensemble sur un trépied avec un axe pivotant pour rendre la lecture encore plus précise sans les tremblements pendant la mesure.
La mesure de la hauteur de l’astre se fait en retirant 90° de X:
2)Avantages/inconvénients
Cette méthode présente le net avantage de mesurer la hauteur d’un astre sans avoir besoin de distinguer l’horizon, on peut donc s’exercer en ville par exemple, la vue de l’étoile suffit. Par contre à bord d’un bateau la mer doit être d’huile et le bateau à l’arrêt pour l’utiliser, sinon le lest bouge et on ne pourra pas mesurer la hauteur. Pour fabriquer un sextant plus élaboré vous pouvez aller lire la page du site sur comment fabriquer un sextant électronique avec arduino.
C’est une loi très simple découverte principalement par le Hollandais Snell. Elle porte sur la réfraction de la lumière dans différents milieux. Cette loi est très importante car elle explique les mirages, pourquoi un objet immergé se déforme, pourquoi les pêcheurs sont assis près du bord quand ils pêchent au lieu d’être debout et une partie des corrections à apporter entre la hauteur vraie et la hauteur instrumentale(voir « la méridienne »). Elle explique aussi comment bien réussir une mayonnaise et gagner au loto(non, là je déconne pardon c’est nul…).
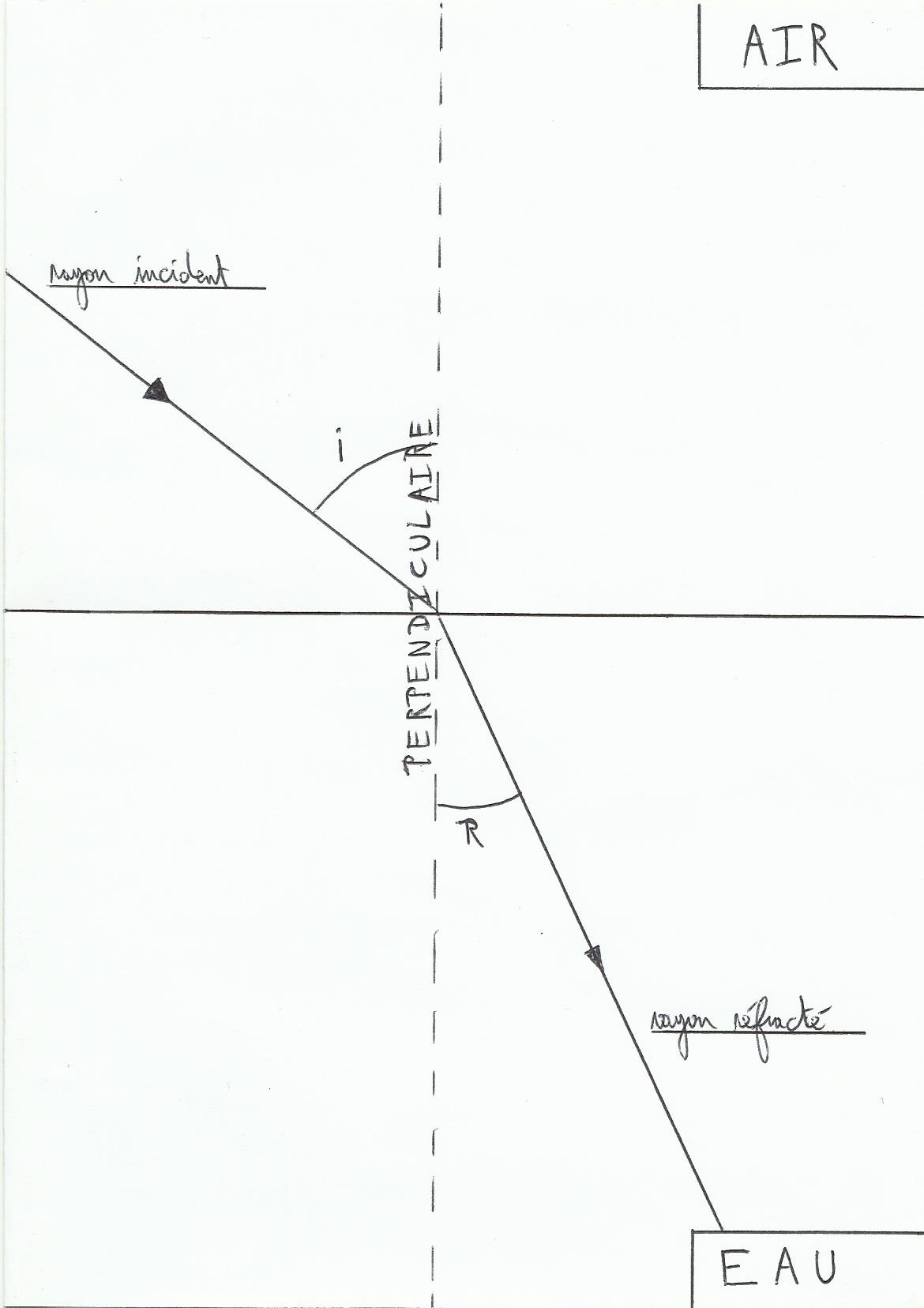
1)Principe
La lumière se propage dans le vide à la vitesse d’environ 300000 km/seconde, mais quand elle traverse un milieu plus dense(par exemple du vide à l’air, de l’air à l’eau ou encore d’un air chaud à un air froid plus dense)elle ralentit, ce qui a aussi pour effet de la dévier. En gros, un rayon qui pénètre dans un milieu plus dense où il ralentit se rapproche de la perpendiculaire à la frontière entre les deux milieux. La lumière s’écarte en sens inverse. Plus la différence de densité entre les milieux est forte plus le rayon est dévié.
On peut mettre tout ça sous forme d’équation, N1*sin(i)=N2*sin(r).
N1 est l’indice de réfraction de l’air et N2 celui de l’eau. C’est une mesure permettant de connaitre la capacité du milieu à dévier la lumière, plus l’indice est élevé et plus la lumière est déviée(l’indice le plus fort est celui du diamant avec 2,42, comme c’est un indice il n’y a pas d’unité). Cet indice est le rapport entre la vitesse de la lumière dans le milieu concerné et celle dans le vide, le vide a donc un indice égal à un, un milieu avec un indice de deux ralentit la vitesse de la lumière par deux(le diamant ralentit donc la lumière presque 2,5 fois plus que dans le vide).
(Remarque: Les outils comme les réfractomètres utilisent cette loi pour mesurer une concentration dans un produit par exemple.)
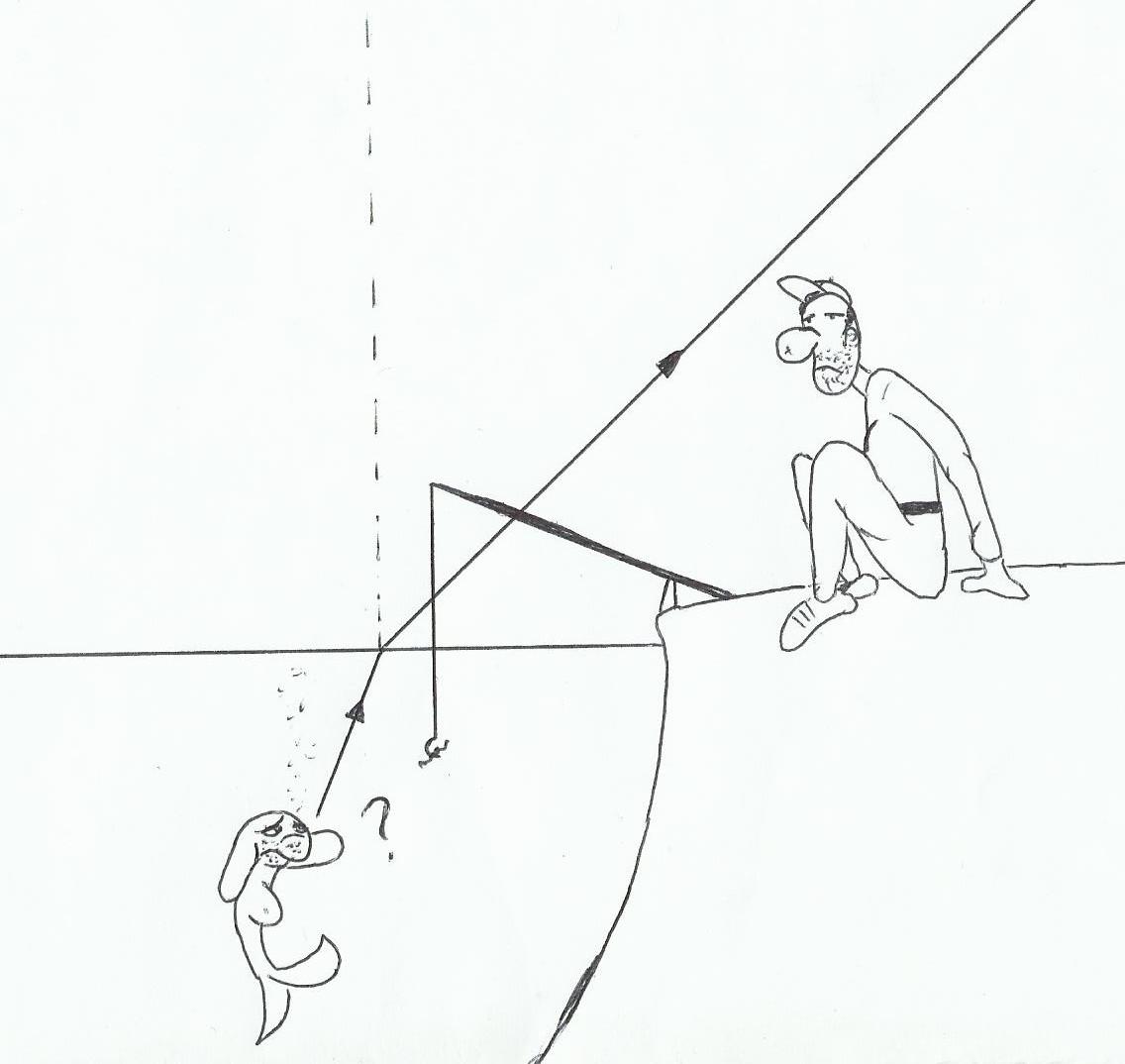
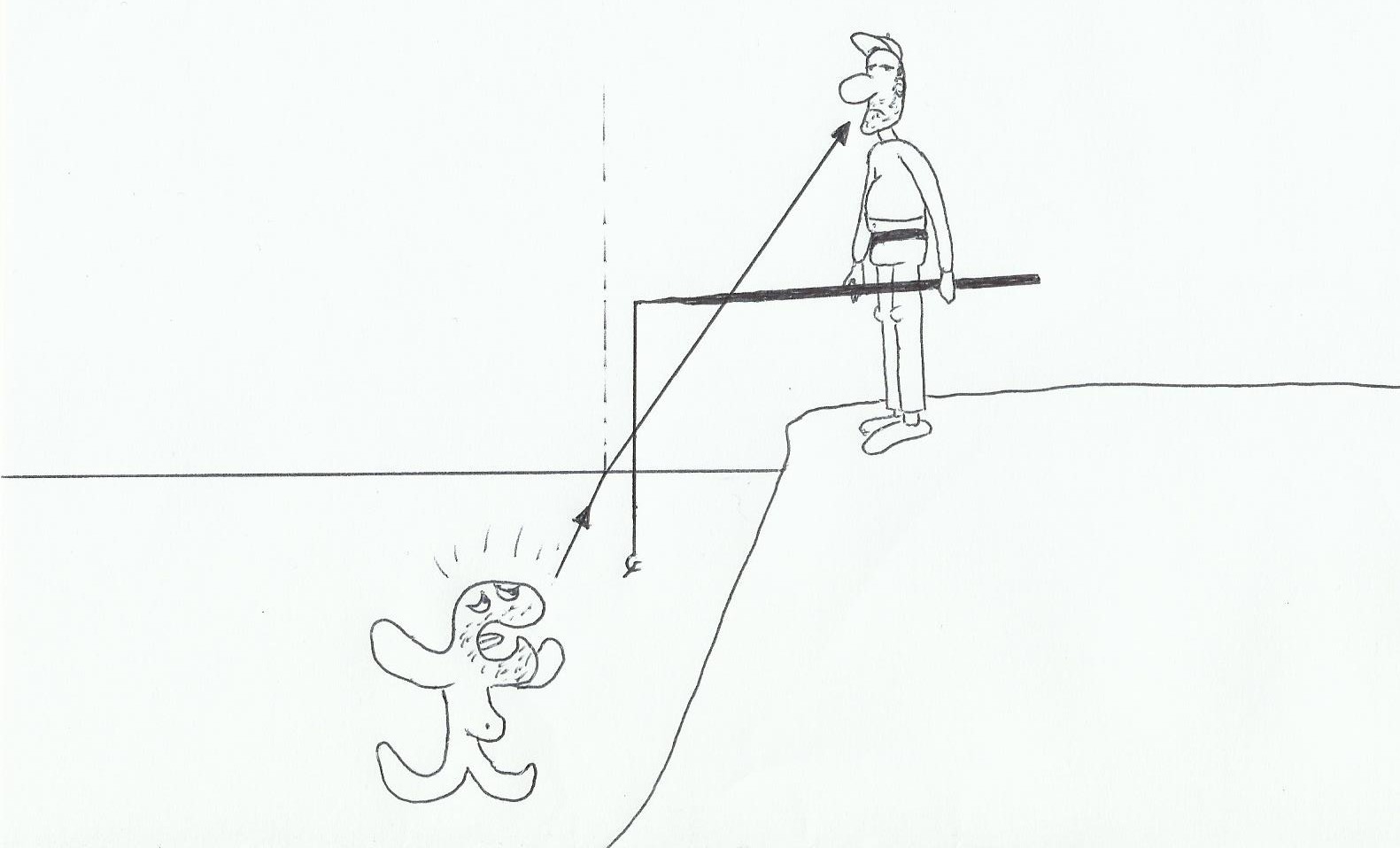
2)Applications
L’un des exemples les plus significatifs est le pêcheur et le poisson. A cause de la déviation de la lumière, les deux ne verrons pas la même chose, du moins pas sous le même angle…
Ici, flipère la truite ne voit pas Mr Igloo…
Damned! Flipère a démasqué le subterfuge!(excusez moi il est tard…).
L’indice de réfraction de l’air variant avec sa température, les rayons sont déviés et l’objet vu semble venir d’ailleurs, c’est le cas des mirages:
Le cas 1 est facilement observable l’été sur les routes goudronnées donc plus aptes à accumuler de la chaleur, on a l’impression de voir comme des vagues se dessiner à l’horizon; en fait c’est le ciel que l’on voit. Si la température varie fortement selon la hauteur au-dessus de la mer, les rayons venant du bas de l’objet seront bien plus déviés que ceux du haut, du coup l’objet vu pourra paraitre inversé.
Autre effet notable, la lumière perçue par le soleil. Le soleil apparait plus haut dans le ciel qu’il ne l’est réellement et plus aplati dans sa hauteur. La première cause est l’indice de réfraction qui change dans les différentes couches de l’atmosphère(plus on descend en altitude, plus l’indice augmente car la densité de l’air augmente)et la seconde cause est le bord inférieur du soleil qui parait plus relevé que le bord supérieur(toujours avec l’histoire de changement de l’indice).
Ce phénomène est à prendre en compte en navigation astronomique, pour déterminer la hauteur vraie du soleil à partir de la hauteur instrumentale, et aussi lorsque l’on utilise les étoiles pour se positionner; il vaut mieux sélectionner des étoiles le plus possible hautes sur l’horizon(dont la lumière émise subit donc moins la déviation). Cette correction est groupée avec trois autres corrections d’angles, on trouve le tableau dans les éphémérides(les trois autres corrections sont la dépression de l’horizon, la parallaxe et le demi-diamètre du soleil).
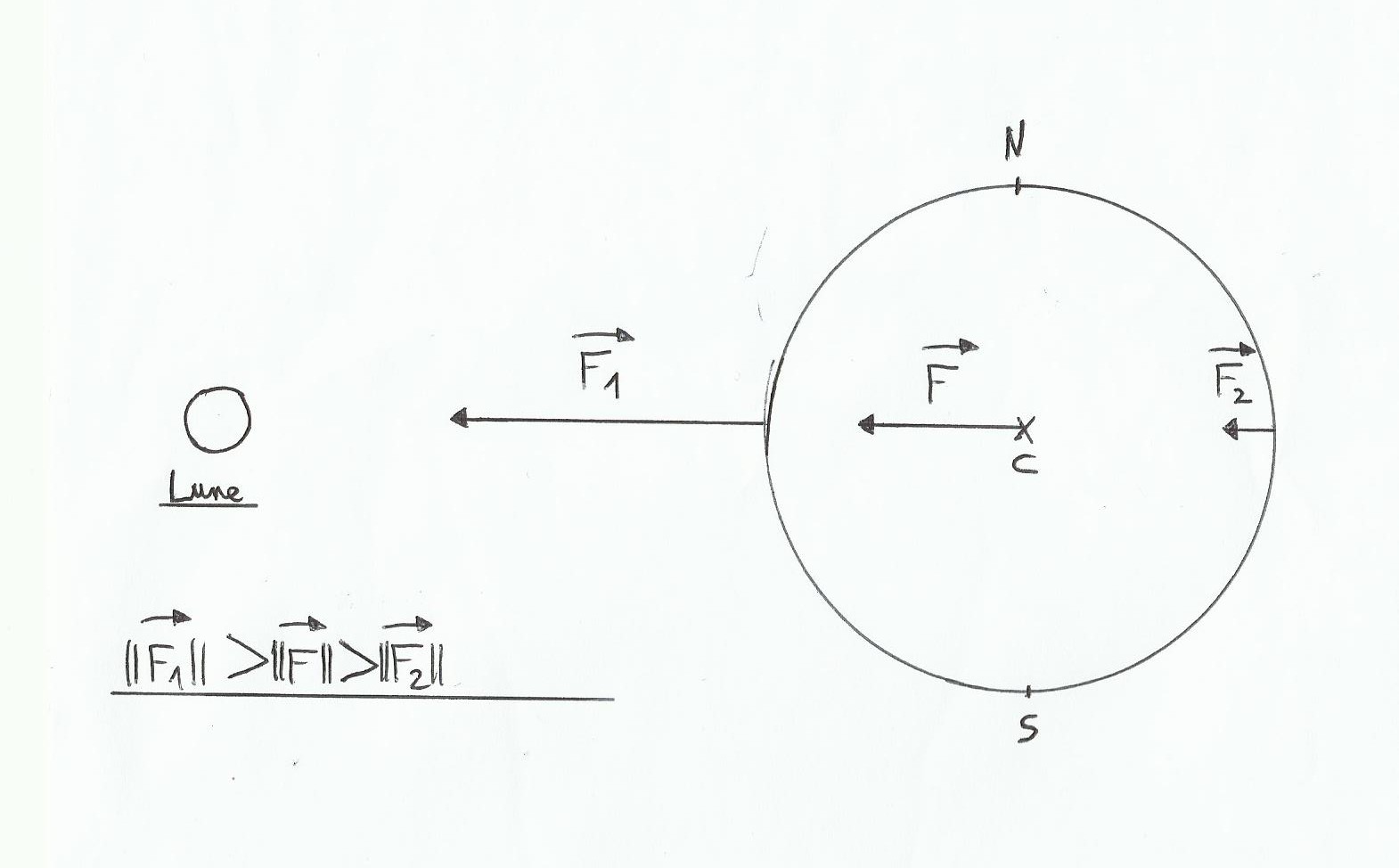
Pour les amateurs de bande dessinées, Newton est le personnage de rubrique à brac(Gotlib) qui a le don de se prendre une pomme sur la tête dans n’importe quelle circonstance, et accessoirement il a été un grand scientifique connu pour ses travaux sur l’optique, le calcul différentiel et dans le cas qui nous intéresse les lois de la gravitation. Ces lois expliquent le phénomène des marées.
1ère loi: la quantité de mouvement(Q) est égale au produit de la masse(M) du corps en mouvement et de sa vitesse(V). Q=M*V, en gros plus un objet est lourd et rapide et plus c’est galère pour l’arrêter.
2ème loi: La somme des forces appliquées à un objet en mouvement accéléré est égale à la masse de cet objet multipliée par sont accélération. Si l’objet est au repos(vitesse constante ou immobile)alors d’après la formule la somme des forces appliquées est donc égale à 0.
3ème loi: Une force appliquée à un objet crée une force antagoniste(ex force de gravité/poussée d’Archimède)de même direction et intensité mais de sens opposé.
4ème loi: La force gravitationnelle(Fg) présente entre deux astres est égale à la constante gravitationnelle(Gn)multipliée par les deux masses des astres(M1 et M2) et divisée par la distance qui les sépare au carré(D carré). C’est une loi de carré inverse, l’intensité de la force de gravité décroît très vite quand la distance d’éloignement de l’astre augmente un peu.
Fg=Gn*M1*M2/D carré
1)En gros comment ça marche?
La terre a une surface majoritaire composée d’eau, cette surface se déforme de quelques dizaines de centimètres au large des océans dans la zone intertropicale sous l’influence de la gravité(Soleil et Lune).
La force de gravité ne se répercute pas de la même manière sur le globe, elle est plus forte à proximité de la Lune. On peut en déduire qu’il y a deux marées hautes aux points d’application des forces F1 et F2(car ici la force de gravité est plus faible, c’est la force centrifuge qui l’emporte). D’après la 4ème loi du début on peut calculer F, F1 et F2.
F=Gn*Mlune/D(terre et lune)au carré
F1=Gn*Mlune/D(terre et lune-rayon terre)au carré
F2=Gn*Mlune/D(terre et lune+rayon terre)au carré
Mlune=7,36*10 puissance 22 kg
D(terre et lune) = 384000000 m
rayon terre = 6350000 m
Gn = 6,67*10 puissance -11 m cubes/kg/secondes
En dégainant sa calculatrice on obtient donc :
F environ égal à 3,3*10 puissance -5 mètres par seconde, F1 3,4*10 puissance -5 mètres par seconde et F2 3,2*10 puissance *-5 mètres par seconde. La force de marée subie à la surface des océans est la différence entre F et F1 et F et F2. Donc cette force équivaut environ à 1*10puissance -6 mètres par seconde avec la Lune seule. En s’amusant à faire pareil avec les données du Soleil(poids et distance terre/soleil)on trouve environ 0,5*10 puissance -6 mètres par seconde(on voit bien la loi du carré inverse de la distance, bien que le soleil soit énorme, sa grande distance de la terre réduit considérablement sont influence. Par contre si la planète Mercure avait de l’eau, ça ferait une sacrée marée perceptible!).
La lune subit de la part de la terre aussi une force de marée bien plus importante(F3), c’est pourquoi elle nous montre toujours sa même face; au cours des siècles cette force a rendu la période de rotation de la lune égale à sa période de révolution autour de la terre, bref c’est un peu le bordel…
rayon lune = 1750000 mètres
masse de la terre = 5,97*10 puissance 24 kg
F3 = Gn*Mterre/D(terre et lune-rayon lune) au carré
F4(centre lune) = Gn*Mterre/D(terre et lune) au carré
la force de marée sur la lune est donc = 3*10 puissance -5 mètres par seconde, 30 fois plus importante que celle exercée par la lune sur terre!
2)Pourquoi à la côte les quelques dizaines de centimètres de différence du large se tranformenten mètres(la vache il est long ce titre!)